
#63 Model Name in URL (revised)
- Download:
- source code
- mp4
- m4v
- webm
- ogv
In the last revised episode, number 162, we showed how to implement tree-based navigation. In it we used an application with a Page model that can have multiple nested pages underneath it.
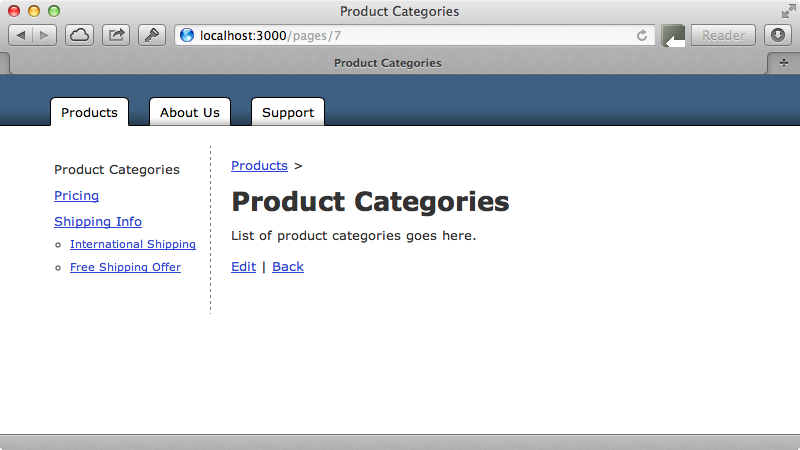
In this episode we’ll be building on this application but focussing on a different topic: how a model is represented in a URL. Rails’ default approach is to use the id of the record from the database but this isn’t very helpful to the user as it doesn’t tell them what page is represented by the URL. Changing the URL to include the page’s name would be better and can help with Search Engine Optimization.
In episode 314 we used the Friendly Id gem to achieve this. While this is a good approach it can be a little heavy if we’re not using all its features. In general it’s better to write something from scratch rather than using a gem if the functionality is easy to add and that’s what we’ll do in this episode.
Let’s take a look at a few different approaches to how we can get the name of the model in the URL. By far the easiest was is to modify a model by overriding the to_param method. This is the method that Rails triggers when it needs to represent a model in a URL and by default it returns the record’s id. We can modify this to return anything we want so for our Page model we’ll have it return the id followed by the page’s name. We’ll call parameterize this so that it’s URL-friendly.
class Page < ActiveRecord::Base attr_accessible :parent_id, :content, :name has_ancestry def to_param "#{id}-#{name}".parameterize end end
When we visit another page in our application now it’s name is included in the URL, for example /pages/9-shipping-info. The page’s id is still included in the URL and this is necessary unless we want to change the way that the record is found. The way this works in Rails is a bit of a trick. When we pass a string to ActiveRecord’s find method it calls to_i on it to convert it to an integer. Ruby will strip off any non-numeric characters at the end of the string and so it will convert “10-international-shipping” to 10 and then find the record with that id. This is why it’s necessary to have the id at the start of the last part of the URL.
Using Slugs
There are times though when we might not want this, maybe for aesthetic reasons or for something more practical like security so that the ids aren’t exposed to the end users. How can use use just the name to find a record? To do this we’ll need to add another column to the database that will store a string value that we can use to identify each record and in that record’s URL. A common convention is to call this slug and it’s a good idea to index this field as we’ll be searching by it every time we load a page in our application. We’ll generate a migration to add this new column.
$ rails g migration add_slug_to_pages slug:index $ rake db:migrate
We can now return this slug attribute when we call to_param in our Page model but before we can do that we’ll need to set it. We could do this in a before_save filter but we’ll need to validate the slug as it’s important that it’s unique and that it exists so instead we’ll use a before_validation filter instead. This will call a method that we’ll call generate_slug that will either return or create a slug.
class Page < ActiveRecord::Base attr_accessible :parent_id, :content, :name validates :slug, uniqueness: true, presence: true before_validation :generate_slug has_ancestry def to_param slug end def generate_slug self.slug ||= name.parameterize end end
In some cases we might want to present the slug field to the user in a form so that they can set it but we won’t do that here. We already have Page records so we’ll need to generate a slug for each of these. We can do that in the console by loading and saving all the existing records.
>> Page.find_each(&:save)
We’re not quite done yet though: we still need to change the way that pages are found in the controller. Instead of finding a Page by its id in the show, edit, update and destroy actions we need to use find_by_slug! (with the exclamation mark so that a 404 error is thrown if a page with a given slug isn’t found).
def show @page = Page.find_by_slug(params[:id]) end
Instead of duplicating this behaviour in the other actions a common practice is to find the model in a before filter. We’ll do this and write a find_page method that will find a page by its slug. We can then remove the line of code that finds a page from each of the relevant actions.
class PagesController < ApplicationController before_filter :find_page, only: [:show, :edit, :update, :destroy] # Some actions omitted. def show end def update if @page.update_attributes(params[:page]) redirect_to @page, notice: "Page was successfully updated." else render :edit end end def destroy @page.destroy redirect_to pages_url end private def find_page @page = Page.find_by_slug(params[:id]) end end
There are different approaches that we could take here instead of using a before filter. One is to rename the find_page method to page and to cache its output so that it only performs the find once. If we then make this method a helper method we can always use it instead of accessing the instance variable directly in both the view and the controller.
private def find_page @page ||= Page.find_by_slug(params[:id]) end helper_method :page
This is a good approach as it’s lazily loaded so the database won’t be hit unless we call this. That means that if we add some caching we might be able to avoid the database find entirely. If you like this kind of thing it’s worth taking a look at the Decent Exposure gem which was covered in episode 259. We’ll stick with the before filter in our application to keep things simple. When we try to find a page by using its slug in the URL now it works and the links to the other pages work as well.
Removing The Controller From The URL
What if we want the page’s slug to be at the root of the URL path instead of having of having to specify pages? In our resources file we have a pages resource. We can pass this a path option where we can specify the prefix we want the URL to have and if we set this to an empty string there will be no prefix. We might not want this to apply to all the actions. For example we might want to keep the pages prefix for the index, new and create actions and in this case we can make two resources entries for pages, one with the path prefix and one without.
Cms::Application.routes.draw do root to: 'pages#index' resources :pages, only: [:index, :new, :create] resources :pages, path: "", except: [:index, :new, :create] end
Now if we visit any page in our application its URL won’t have /pages in it. If we go to the page to create a new page, the path will still be /pages/new with the prefix. We have to watch out when we take this approach as we now have the type of catch-all route that needs to be placed at the bottom of the routes file. For example if we had the route get "foo" in the routes file below the two pages routes this route would never be triggered as the pages#show action will be triggered instead. Also we need to keep in mind that path we visit without a slash in it will also trigger pages#show and will raise a RecordNotFound exception and will display a 404 error to the user. This is what we want to happen but a database query will always be made so there may be performance issues related to this. If we use this approach is also a good idea to add a validation to the slug to ensure it doesn’t conflict with existing URLs, such as the URLs for signing-up and logging-in.
validates :slug, uniqueness: true, presence: true, exclusion: {in: %w[signup login]}
Nested Page Names
We’ll cover one more technique in this episode: nesting page names in routes. Our pricing page is nested under products so we want its URL to be /products/pricing instead of just /pricing. This won’t currently work and the reason for this is that Rails uses the colon operator when it grabs the id for the resource’s route and this doesn’t accept slashes. We can instead uses an asterisk instead of a colon and this will grab the entire path including any slashes. We can use this to create a route that points to pages#show.
Cms::Application.routes.draw do root to: 'pages#index' resources :pages, only: [:index, :new, :create] resources :pages, path: "", except: [:index, :new, :create] get '*id', to: 'pages#show' end
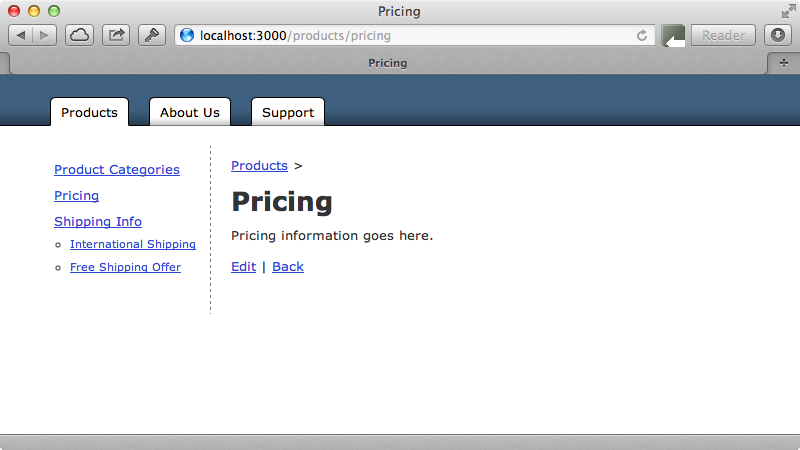
Now when we visit /products/pricing the show action is triggered with an id of /products/pricing. In a real application we should check the entire path to make sure the parents are correct but in our example app we’ll just split the id parameter on the slash character and search for a slug based on the last element.
def find_page @page = Page.find_by_slug(params[:id].split('/').last) end
When we visit /products/pricing now we see the correct page.
The links to nested pages still don’t have the correct path, however. To fix this we can use a helper method whenever we need to link to a page. We’ll write a nested_page_path in the PagesHelper to do this. As we’re using the Ancestry gem it’s easy to get the page’s ancestors. We can then map all the to_param calls to convert each one to a URL format then join them with a slash.
module PagesHelper def nested_page_path(page) '/' + (page.ancestors + [page]).map(&:to_param).join('/') end end
We can now use this wherever we need to add a link to a page, such as in our sidebar.
<%= link_to_unless_current page.name, nested_page_path(page) %>Now when we click on the links in the sidebar we’re redirected to the full nested path.
