
#414 Batch API Requests pro
- Download:
- source code
- mp4
- m4v
- webm
- ogv
Below is a screenshot from a simple Todo list application. With it users can add tasks and then mark them as complete or incomplete.
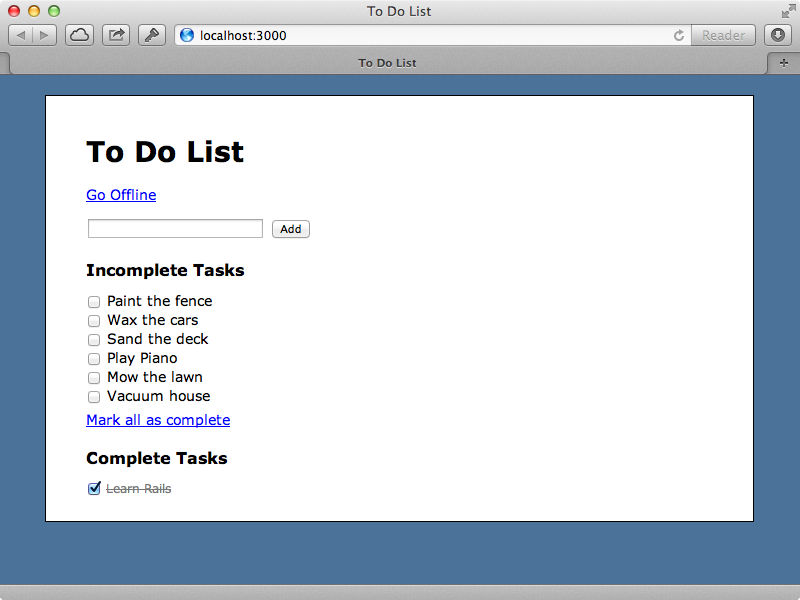
The behaviour of this app is entirely client-side JavaScript and it communicates with the Rails backend through a JSON API to persist the data. This means that if we reload the page any changes we make stick around. We can mark all the incomplete tasks as complete by clicking the “Mark all as complete” link but this operation isn’t very efficient as it makes a separate JSON request to the server for each task that needs to be changed. It would be better if these were done in one go which brings us to the topic of this episode: handling a batch of actions through a single request.
One way to do this, that would work well in our application, is to add another controller action to handle the bulk behaviour. Our TasksController currently has the standard seven RESTful actions and we could add, say, an update_many action which takes an array of ids and finds the relevant tasks and updates them. What, though, if we want to perform some other actions at the same time, maybe destroying some records or creating some new ones, or maybe even calling an action on a different controller? What we want is something like the feature provided by Facebook’s Graph API called “Batch Requests” which allows us to trigger multiple API actions in a single request by supplying an array of JSON data including a HTTP method and a URL to trigger. These requests will respond with an array containing data about the status of each part of the request. One advantage of this approach is that is allows us to trigger any number of controller actions in a batch without having to modify the details of our Rails application once it’s set up. This means that we don’t need to add any new controller actions.
To implement this feature we’ll use Rack Middleware. This might feel a little like a hack but it will work well enough. If we run the rake middleware command we’ll see a list of the middleware that each request goes through. To see this list, and for a description of what each part does, take a look at episode 319. We need to decide where in the middleware stack we should add our middleware to handle batch requests. This will take a single request and simulate multiple other requests through it. If we were to after, say, Rails::Rack::Logger it would log the batch request but not the details of each individual request in the batch. We’ll add our middleware early in the stack so that it’s almost as if our Rails application is being triggered for each separate request. To add middleware to the top of our stack we need to modify our application’s config file like this:
config.middleware.insert_before 0, "BatchRequests"
The first argument specifies the position of the new middleware so using 0 means that our middleware, which we’ve called BatchRequests, will be placed at the top of the stack. We’ll write it in a new /app/middleware directory. A piece of middleware is simply a class with an initialize method which accepts a Rack application and a call method that takes a Rack environment hash so that it can call the app through it.
class BatchRequests def initialize(app) @app = app end def call(env) @app.call(env) end end
Here, though, we don’t simply want to call the application once. Instead we want to parse the parameters that are passed in and trigger the app for each of the different requests, customizing the environment that we pass in to each one. We won’t get into that quite yet, though, instead we’ll add some code that will trigger this behaviour when the request URL matches something specific. This middleware will be triggered for every request in our application so one of the first things we want to do is make sure that the path is relevant to it. If it isn’t we’ll just delegate to the next middleware. If the path matches we want to trigger the request multiple times, changing the environment hash each time and then respond and we’ll respond with a 200 response and a content type of application/json. The response’s body should include all the requests that are made, but for now we’ll just inspect the environment hash so that we can see what’s in it.
def call(env) if env["PATH_INFO"] == "/batch" [200, {"Content-Type" => "application/json"}, [env.inspect]] else @app.call(env) end end
After restarting our application it should behave just like it did before until we call the /batch path. When we do this our new middleware will pick this up and display the details of the environment hash.
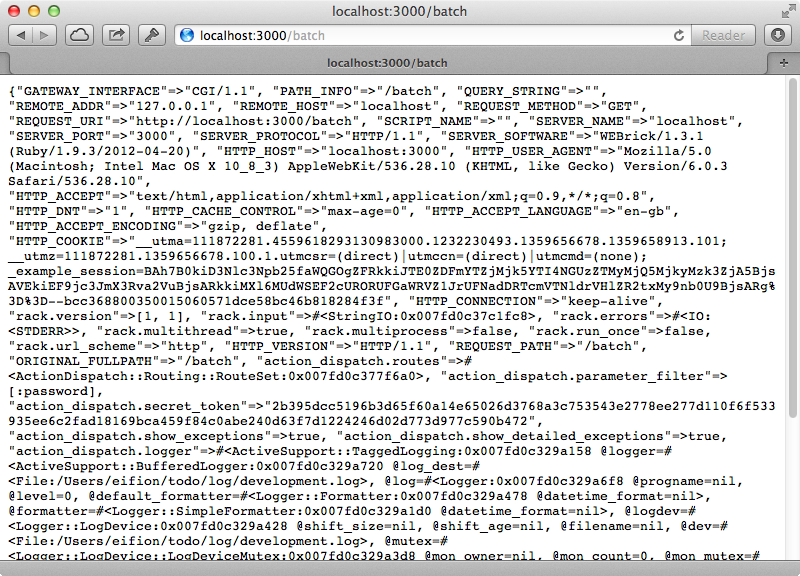
This contains information specific to this request and we’ll need to change some of it to simulate other requests, including PATH_INFO, QUERY_STRING and REQUEST_METHOD. There is also the rack.input environment option which is going to be the body of the request. There are some other settings here that look like they might need to be changed such as REQUEST_PATH and REQUEST_URI but these are set by WebRick and aren’t really part of the Rack specs. There are more details about Rack Specs and what the options do in the documentation. To start we’ll try manually setting these environment options to simulate a different request from what was actually made.
def call(env) if env["PATH_INFO"] == "/batch" env["REQUEST_METHOD"] = "GET" env["PATH_INFO"] = "/tasks.json" env["QUERY_STRING"] = "" env["rack.input"] = StringIO.new("") @app.call(env) else @app.call(env) end end
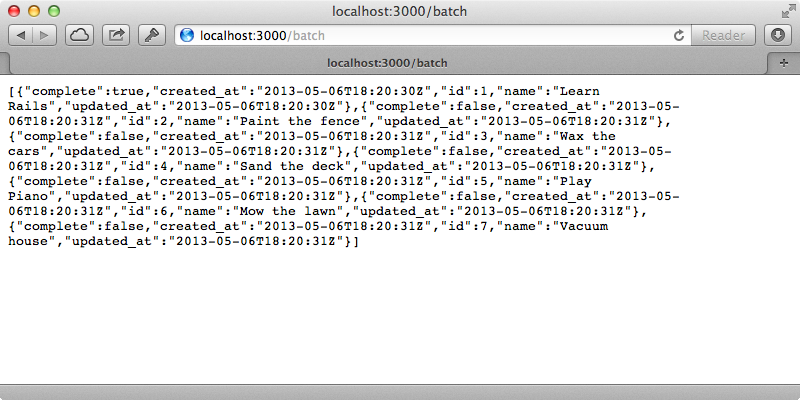
Here we’ve changed the path to /tasks.json so that the request becomes a JSON request and also some of the other options we mentioned earlier. We then call our app with these new options. We need to restart the server for the changes to be picked up but after we do so and we reload the page we see a list of tasks in JSON so any request we make to /batch will be converted a request to /tasks.
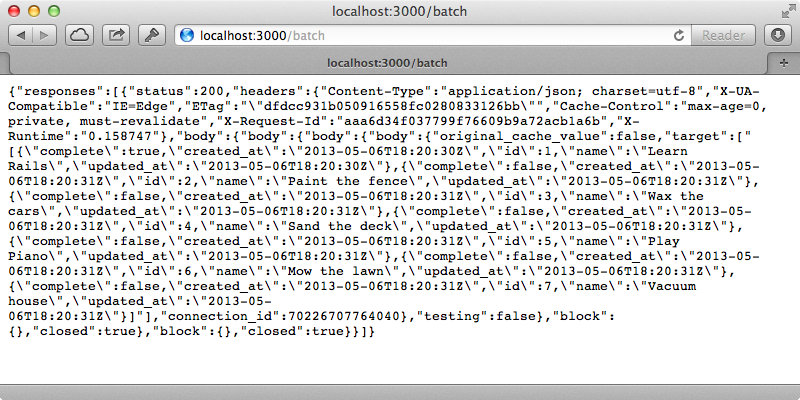
We want to report the full response to the user including the status, the headers and the body of the response. We’ll put all this into a hash and save it so that we can report it back to in an array. This way they will see all the responses for each request that they passed in through the API. When we try this we may sometimes get a deadlock error. This is because Rack::Lock isn’t properly releasing the mutex lock. To get around this we need to close the body of the response.
def call(env) if env["PATH_INFO"] == "/batch" env["REQUEST_METHOD"] = "GET" env["PATH_INFO"] = "/tasks.json" env["QUERY_STRING"] = "" env["rack.input"] = StringIO.new("") status, headers, body = @app.call(env) body.close if body.respond_to? :close response = {status: status, headers: headers, body: body} [200, {"Content-Type" => "application/json"}, [{responses: [response]}.to_json]] else @app.call(env) end end
When we reload the page now, after another server restart, we can see the responses details wrapped in an array.
The next step to finish off our middleware is to replace the static request values with dynamic ones based on the parameters submitted with the request. We don’t have access to the params hash here so we’ll create a request object based on the Rack::Request. This will allow us to access request parameters by using the hash notation. We’ll look for a parameter called requests which will contain some JSON data and use JSON.parse to parse it. This is very strict and if there are any errors in the JSON it will raise an exception so we could add some error handling, although we won’t do so here. Once parsed, this parameter will return an array of request options that we can use to override the environment hash. We want to create a new response for each one, depending on the request settings so we’ll map all the responses together and return them in the JSON result. For each request passed in we’ll override the relevant environment variables. We’ll split the url variable into the path and query string and pass them in to PATH_INFO and QUERY_STRING and also set rack.input to the body. To keep the call method clean we’ll extract the code to process a request out into a new method. There’s a potential problem here that we’ll need to address as we’re using the same environment hash for each request but this might be modified during the requests so instead of passing the hash into process_request we’ll pass a copy of it in, using deep_dup in case there are any nested hashes. We’ll do the same when we create the Rack::Request from the environment as this call can modify the hash.
def call(env) if env["PATH_INFO"] == "/batch" request = Rack::Request.new(env.deep_dup) responses = JSON.parse(request[:requests]).map do |override| process_request(env.deep_dup, override) end [200, {"Content-Type" => "application/json"}, [{responses: responses}.to_json]] else @app.call(env) end end def process_request(env, override) path, query = override["url"].split("?") env["REQUEST_METHOD"] = override["method"] env["PATH_INFO"] = path env["QUERY_STRING"] = query env["rack.input"] = StringIO.new(override["body"].to_s) status, headers, body = @app.call(env) body.close if body.respond_to? :close {status: status, headers: headers, body: body.join} end
Our middleware should now be able to process multiple requests so once we’ve restarted the server we can try this out through Curl, setting the requests parameter to some JSON that contains some request details. We’ll pass an array of two requests, each with method and url parameters and make requests for two separate tasks.
$ curl -d 'requests=[{"method":"GET", "url":"/tasks/1.json"},{"method":"GET", "url":"/tasks/2.json"}]' localhost:3000/batch
{"responses":[{"status":200,"headers":{"Content-Type":"application/json; charset=utf-8","X-UA-Compatible":"IE=Edge","ETag":"\"8d36e61e9e2bec4d7a65770eea3600fb\"","Cache-Control":"max-age=0, private, must-revalidate","X-Request-Id":"a2533653452437af11db055c59d8389d","X-Runtime":"0.156114"},"body":"{\"complete\":true,\"created_at\":\"2013-05-06T18:20:30Z\",\"id\":1,\"name\":\"Learn Rails\",\"updated_at\":\"2013-05-06T18:20:30Z\"}"},{"status":200,"headers":{"Content-Type":"application/json; charset=utf-8","X-UA-Compatible":"IE=Edge","ETag":"\"348ff78475b7ea596cc9b2fc4cce40c7\"","Cache-Control":"max-age=0, private, must-revalidate","X-Request-Id":"ed0754a7121c36ef21c697380123458d","X-Runtime":"0.007084"},"body":"{\"complete\":false,\"created_at\":\"2013-05-06T18:20:31Z\",\"id\":2,\"name\":\"Paint the fence\",\"updated_at\":\"2013-05-06T18:20:31Z\"}"}]}When we do this we get our responses hash containing details about both the tasks.
Integrating What We’ve Done Into Our App
Now that we’ve got this working let’s try to integrate this into our JavaScript. Our goal is to have the “mark all as complete” link trigger a single request that will mark all of the uncompleted tasks as complete. The CoffeeScript for this client-side behaviour is rather complex, but we don’t be going into too much detail about it as it depends on the client-side framework you’re using in your application. All we’re using here is Mustache to handle rendering templates. Our code includes a completeAll function that is triggered whenever that link is clicked.
completeAll: (event) =>
event.preventDefault()
$('#incomplete_tasks').find('input[type=checkbox]').click()This function is simple and goes through each incomplete task, clicking on each one’s checkbox to simulate the user marking each task as complete. Clicking a checkbox triggers an update function which finds the task and marks it as either complete or incomplete depending on whether the checkbox was checked. It then removes the checkbox from its list, renders it in the other list then saves it to the database by making an AJAX request which makes a PUT request to the task’s URL.
update: (event) =>
checkbox = $(event.target)
task = @find(checkbox.data('id'))
task.complete = checkbox.prop('checked')
checkbox.parent().remove()
@render(task)
@save(task)
save: (task) ->
$.ajax
type: "PUT"
url: "/tasks/#{task.id}.json"
data: {task: {complete: task.complete}}This save function is what we’re going to focus on changing. Instead of saving a task immediately when a checkbox changes we’ll store all of the requests in a batch and push them all at once to the server when we need to.
class ToDoList
constructor: ->
@requests = []
@tasks = $('#tasks').data('tasks')
for task in @tasks
@render(task)
$('#tasks').on('submit', '#new_task', @add)
$('#tasks').on('change', 'input[type=checkbox]', @update)
$('#tasks').on('click', '#complete_all', @completeAll)
$('#tasks').on('click', '#toggle_offline', @toggleOffline)
save: (task) ->
@requests.push
method: "PUT"
url: "/tasks/#{task.id}.json"
body: $.param(task: {complete: task.complete})First we create an array called @requests in the class’s constructor and then in save we push each request into that array. Each request needs to be in the same format as our API so we push an object with method, url and body properties. To get the body into the correct format we use $.param to make it into an HTTP request body. Any changes we make are now no longer synced to the server. We’ll write a new sync function that we can call when we want to do that. This will make a POST request to our /batch URL, passing in the @requests array. This needs to be formatted as JSON and we’ll use JSON.stringify to do this. This works in most modern browsers although we can add the json.js library if backwards-compatibility is important. Finally, we clear the array of requests.
sync: ->
$.post("/batch", requests: JSON.stringify(@requests))
@requests = []We could move the requests off into a separate array temporarily until we get a response back from the server telling us that all the requests have been saved successfully. We could then either resend them or report to the user that the update failed. We won’t be covering that in this episode, though.
We don’t call sync anywhere yet. We could call it at the end of save but we might not want to sync every time we save, instead letting the changes batch up. We’ll define a variable called @offline that will allow us to into offline mode whenever we don’t want to contact the server to sync the changes. We can use this to temporarily go into offline mode when we want to batch up changes. We’ll use this in completeAll so that the updated tasks are sent in one go.
completeAll: (event) =>
event.preventDefault()
@offline = true
$('#incomplete_tasks').find('input[type=checkbox]').click()
@offline = false
@sync()
sync: ->
unless @offline
$.post("/batch", requests: JSON.stringify(@requests))
@requests = []Let’s see if this works. We have a few incomplete tasks and when we click “mark all as complete” we’ll see that only a single batch request is made and that all the responses are returned.
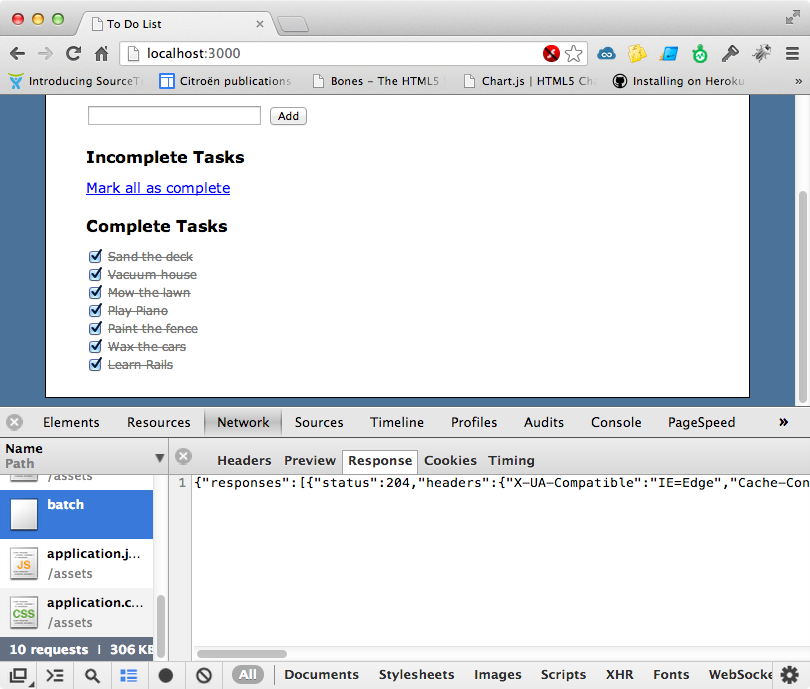
If we change the status of a single task a new batch request is sent and any changes we make are persisted, which we can see by reloading the page. One of the killer features of doing this kind of thing is that it makes it easy to support an offline mode. We already have this partially set up with a “Go Offline” link. Clicking on this toggles the value of our @offline variable and the link’s text. If we add a call to sync here any changes we make will be synced when we go back online.
toggleOffline: (event) =>
event.preventDefault()
@offline = !@offline
$('#toggle_offline').text(if @offline then "Go Online" else "Go Offline")
@sync()If we go offline now and make changes to the tasks no requests are made to the server until we go back online when a single batch request will be made to sync everything that we did while offline. This is great for mobile apps that might have a a spotty data connection. If we’re doing this we could store the requests array into the browser’s internal database so that it can be persisted even when the user closes the session.
Even though we have this batch API system in place there are sill advantages to going with a separate controller action such as the update_many action we considered earlier. We could easily optimize this into a single database query instead of having separate actions trigger different database queries. Our bulk update approach is fully compatible with the batch system, though. We just trigger the update_many path instead of batch.
Before we finish we’ll point out something called HTTP pipelining which can be used as an alternative to our batch request system. This does have certain limitations, though. It isn’t fully compatible across all web browsers and only supports GET requests. Adding a batch system is easy to do with Rack Middleware, although our code isn’t really production-ready. To do so we’d need to handle those cases where errors might occur and also limit the number of requests that we accept, among other things.
Batching the creation of records is tricky as we don’t have an id to reference until we get a response back from the server. We could assign a unique identifier on the client-side and send this to the server to be stored in the database so that records can be uniquely identified before they’ve been saved.
