
#307 ElasticSearch Part 2 pro
- Download:
- source code
- mp4
- m4v
- webm
- ogv
In the previous episode we showed you how to add full-text searching to a Rails application with Elasticsearch and the Tire gem. Our application has a page that shows a list of articles and we can now search them by keyword.
Elasticsearch supports many more features than we covered last time so in this episode we’ll expand on what we’ve done so far and show some additional features and configuration options we can add to improve the search functionality.
Refining Searches With Search Terms
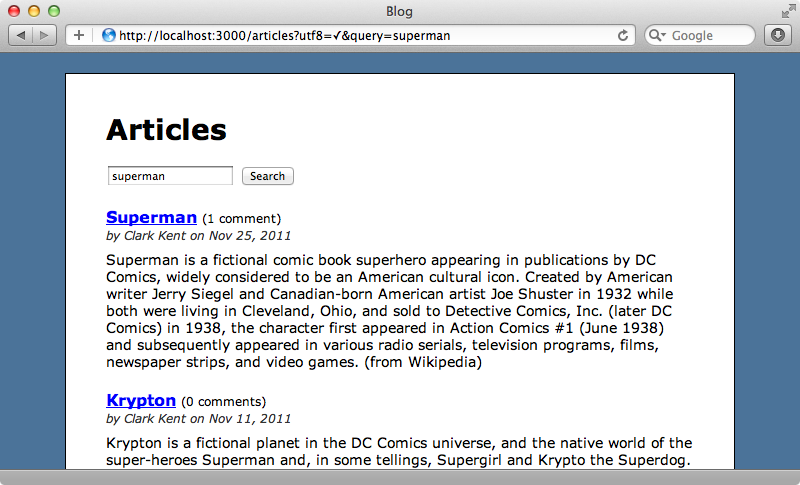
We’ll start by showing some additional options that we can use in the search text field. Our current search is for superman and this returns articles that have that text anywhere within them.
If we only want to find articles whose name matches “Superman” we can use the search term name:superman. Similarly if we want to perform a wildcard search we can use an asterisk. Searching for name:*man will give us all the articles with names that end with “man”, in this case Batman and Superman.
To search for phrases we use quotes. A search for "fictional character" will return only the articles that contain that phrase. Without the quotes the search will return any article that contains either “fictional” or “character”. We get the same results if we search for fictional OR character. If we search for fictional AND character only the articles that contain both of those words will be returned. Finally, a search for fictional NOT character will return articles that contain “fictional” but not “character”.
There are a number of ways to customize the search behaviour. If we look at the Query String Query page of Elasticsearch’s guide we’ll see a list of all of the options we can use, one of which is default_operator. We’ll set this to AND rather than the default OR so that only articles matching all the entered terms are returned. We do this in the Article model which is where the search is performed. We need to add the default_operator option to the query method.
def self.search(params) tire.search(load: true) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} end end
Now when we search for fictional character only the articles that match both keywords will be returned.
Sorting
By default the returned articles are sorted by relevance but we can customize this by using the sort method in the search block and passing it a by option. We can pass in a direction, too.
def self.search(params) tire.search(load: true) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? end end
We’ve made this the default sort, but only if no search query has been entered. If the user types in a search term the results will still be sorted by relevance.
Pagination
Another common requirement is pagination and we can add pagination options to the search method.
def self.search(params) tire.search(load: true, page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? end end
We set the page option to be the value of the page param and we’ve set the pagination to show two articles per page. We also need to add a gem to handle pagination such as will_paginate or Kaminari. We’ll add will_paginate to the gemfile then run bundle to install it.
source 'http://rubygems.org' gem 'rails', '3.1.3' # Bundle edge Rails instead: # gem 'rails', :git => 'git://github.com/rails/rails.git' gem 'sqlite3' # Gems used only for assets and not required # in production environments by default. group :assets do gem 'sass-rails', '~> 3.1.4' gem 'coffee-rails', '~> 3.1.1' gem 'uglifier', '>= 1.0.3' end gem 'jquery-rails' gem 'tire' gem 'will_paginate'
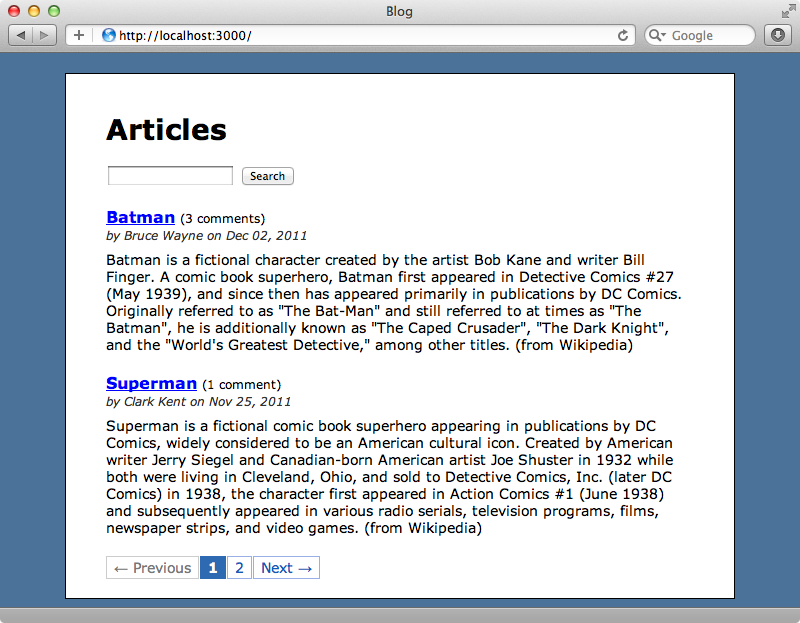
We can now add a call to will_paginate at the bottom of the articles page.
<%= will_paginate @articles %>When we reload the page now we’ll see only two articles and the pagination links. (We’ve already added some CSS to style the pagination.)
A quick note here about Tire’s DSL. Tire uses blocks a lot and inside each one the current context changes. This means that inside the tire.search block self doesn’t refer to the Article class, but will instead be a Tire search object. This gives us a nice DSL that lets us call methods against the class directly but it can cause confusion if we need to use other class methods inside the block. If this becomes a problem we can pass a parameter to the block and access the methods through that parameter.
def self.search(params) tire.search(load: true, page: params[:page], per_page: 2) do |s| s.query { string params[:query], default_operator: "AND" } if params[:query].present? s.filter :range, published_at: {lte: Time.zone.now} s.sort { by :published_at, "desc" } if params[:query].blank? end end
This approach has the advantage that inside the block self still refers to the Article class. It works with most of the blocks that Tire uses including the query and sort blocks but the default syntax is cleaner so we’ll stick with that here.
Adding More Fields To The Index
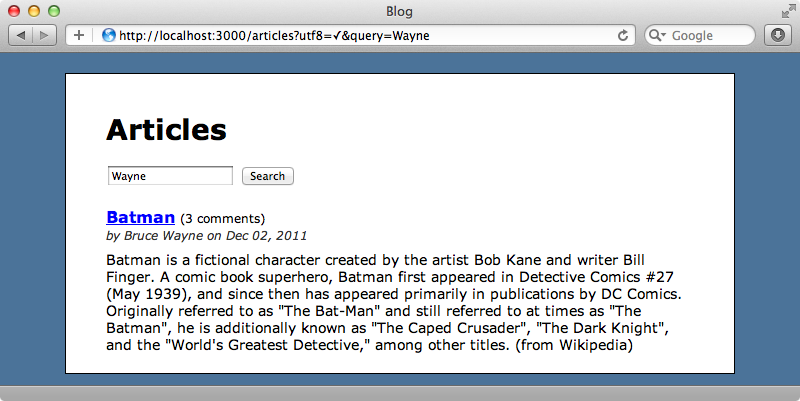
Now that our search behaviour is feature complete we’ll move on to indexing. All of the attributes in each Article are indexed but the attributes of the associated models, e.g. Author and Comment aren’t. If we search for clark no articles will be returned as this attribute isn’t indexed.
To add these associated attributes we must override the model’s to_indexed_json method. This method returns a JSON string containing the data that will be indexed. To add the author name we call to_json and pass it any extra data we want to include. To include the author’s name we call methods with an array of the methods that should be called. We’ll need an author_name method that returns the article’s author’s name.
def to_indexed_json to_json(methods: [:author_name]) end def author_name author.name end
As our application uses Rails 3.1 this will all work perfectly as to_json will serialize the article’s attributes and, in this case, include the associated author’s name. In earlier versions of Rails this will include a root element but we can remove this by adding this line of code in the model.
self.include_root_in_json = false
For these changes to take effect we need to reindex the articles’ records and Tire provides a Rake task for doing this. This task expects the name of the class we want to reindex and we also need to pass in the FORCE argument as we’re rebuilding an existing index. As our Article class is inside the Rails environment we have to load the environment so we prefix the task with the environment task.
$ rake environment tire:import CLASS=Article FORCE=true
[IMPORT] Deleting index 'articles'
[IMPORT] Creating index 'articles' with mapping:
{"article":{"properties":{}}}
[IMPORT] Starting import for the 'Article' class
--------------------------------------------------------------------------------
4/4 | 100% ###########################################################
================================================================================
Import finished in 0.36422 secondsThis task requires some kind of pagination so if you see an error about an undefined paginate method you’ll need to add will_paginate or Kaminari to the application’s gemfile before running it. Now that we’ve reindexed the articles we can search for an author and we’ll see the matching articles returned.
Fetching All of The Data From The Index
When we perform the search in our Article model we pass it the option load: true. This means that the matching articles are loaded from the database rather than using the attributes from the index. We had to set this in the previous episode as we hadn’t indexed all of the attributes necessary to display the articles. If we were to add these attributes to the index we could remove this option and this would give us better performance as we wouldn’t have to load the records from the database.
To do this we need to remove everything in the view that displays data through an association. For example we call article.author.name to display the author’s name and article.comments.size to show the number of comments. We need to replace these with methods from Article so that they can be easily fetched from the index. We already have an author_name method and next we’ll write a comment_count method to return the number of comments.
<div id="articles"> <% @articles.each do |article| %> <h2> <%= link_to article.name, article %> <span class="comments">(<%= pluralize(article.comment_count, 'comment') %>)</span> </h2> <div class="info"> by <%= article.author_name %> on <%= article.published_at.strftime('%b %d, %Y') %> </div> <div class="content"><%= article.content %></div> <% end %> </div>
Next we’ll add that method in the model and add the method to the index.
def to_indexed_json to_json(methods: [:author_name, :comment_count]) end def author_name author.name end def comment_count comments.size end
Since we’ve changed the index we’ll need to rebuild it using the command we ran earlier.
$ rake environment tire:import CLASS=Article FORCE=true
Now that we’re storing all the attributes that we display on the page in the index we can remove the load: true option that loads the articles from the database.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? end end
Now that we’ve made these changes does our articles page work? It doesn’t. Instead of the list of articles we’re expecting we get an “undefined strftime method” exception.
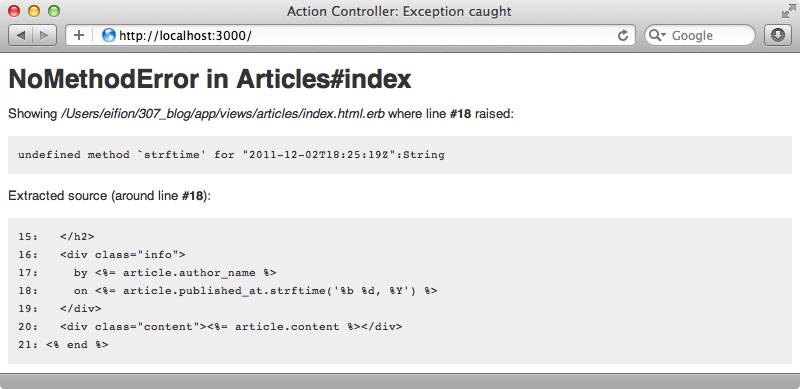
Each article’s published_at attribute is stored as a string in the index rather than as a DateTime and we can’t call strftime on a string. A quick fix for this is to call to_time on this attribute before calling strftime.
<div class="info"> by <%= article.author_name %> on <%= article.published_at.to_time.strftime('%b %d, %Y') %> </div>
When we reload the page now it works and its fetching all its data from the index instead of from the database.
Tire even provides a persistence module which allows us to store records entirely on Elasticsearch so we don’t need a separate database. There are details on how to do this towards the bottom of Tire’s README file.
Using Custom Mappings
There may be a time when we need more control over how the attributes are indexed in Elasticsearch. Currently we’re just passing it a simple JSON string and this generally works well enough. If we need to fine-tune things, though, it’s best to create a mapping. We do this by calling mapping in a model. This takes a block and inside that block we use indexes to define the attributes we want indexed.
class Article < ActiveRecord::Base belongs_to :author has_many :comments include Tire::Model::Search include Tire::Model::Callbacks mapping do indexes :id, :type: 'integer' indexes :author_id, type: 'integer' indexes :author_name indexes :name, boost: 10 indexes :content indexes :published_at, type: 'date' indexes :comment_count, type: 'integer' end # Rest of class omitted end
The type defaults to a string but we can change that by specifying the type option. There are other options we can use here and for the name attribute we’ve used boost to prioritize the name option. This defaults to 1 but if we make it higher then any matching keywords found in that attribute will give given a higher relevance than if the same keywords were found in the other attributes.
We can also use the analyzer option. This option changes how the text is indexed; a different analyzer may split words differently or change how casing is handled. Analyzers are out of the scope of this episode but it’s good to know that this option is available if we need it.
For more information about the options we can pass to indexes take a look at the Core Types page in the documentation. There’s more information about analyzers in the documentation, too.
Once we’ve defined our index mapping we’ll need to reindex the data again.
$ rake environment tire:import CLASS=Article FORCE=true
[IMPORT] Deleting index 'articles'
[IMPORT] Creating index 'articles' with mapping:
{"article":{"properties":{"id":{"type":"integer"},"author_id":{"type":"integer"},"author_name":{"type":"string"},"name":{"boost":10,"type":"string"},"content":{"type":"string"},"published_at":{"type":"date"},"comment_count":{"type":"integer"}}}}
[IMPORT] Starting import for the 'Article' class
--------------------------------------------------------------------------------
4/4 | 100% ###########################################################
================================================================================
Import finished in 0.23757 secondsNote that this time we see the mapping details as the data is reindexed.
Facets
Now that the new index is set up we’ll add some faceted search functionality. We’ll add a list of authors to the page as links so that users can click one to further filter the search results. To add facets we need to modify the code in the model’s search block by making a call to facet.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? facet "authors" do terms :author_id end end end
We need to give the facet a name and pass it a block. Inside it we set up a terms facet for the author_id attribute. To display the facets in the view we can add this code.
<div id="facets"> <h3>Authors</h3> <ul> <% @articles.facets['authors']['terms'].each do |facet| %> <li> <%= link_to_unless_current Author.find(facet['term']).name, params.merge(author_id: facet['term']) %> <% if params[:author_id] == facet['term'].to_s %> (<%= link_to "remove", author_id: nil %>) <% else %> (<%= facet['count'] %>) <% end %> </li> <% end %> </ul> </div>
In this code we list the authors that the user can filter the articles by. We fetch the authors by calling @articles.facets and using the name of the facet in the model and we call ['terms'] on this to fetch each facet. We then create a link for each author except the currently selected one. We can get the id for each one by calling facet['term'] and we use this to fetch each author so that we can display their name in the link.
If there’s an author_id parameter present then the articles have already been filtered by that author so we’ll also add a “remove” link for that author. For the other’s we’ll show the number of articles written by that author.
Here’s now the new part of the page looks. We’ve already added some CSS to make it look pretty.
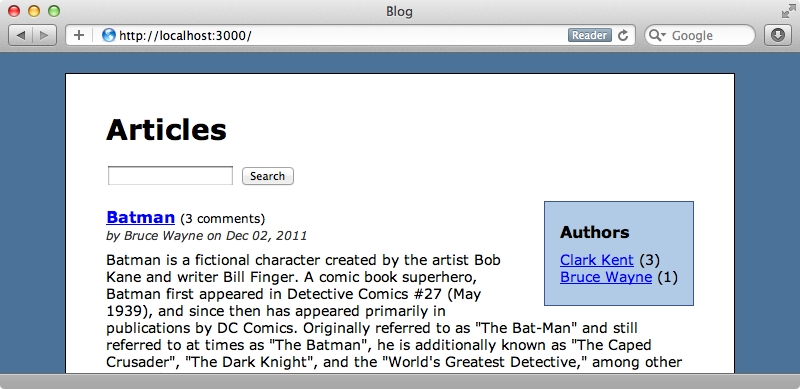
When we select one of the authors the articles will be filtered by that author. We can then click the “remove” link next to the selected author’s name to remove that filter.
We need to set up the search so that it takes account of the selected author. We do this by adding another filter to the search block.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} filter :term, author_id: params[:author_id] if params[:author_id].present? sort { by :published_at, "desc" } if params[:query].blank? facet "authors" do terms :author_id end end end
This filter is a term filter and it filters by the author_id if it’s present in the params. If we reload the page now and select an author the articles will be filtered so that only those written by that author are shown.
There’s a small problem with this, however. If we have no author selected the authors panel shows that there are three articles by Clark Kent, but when we click “Clark Kent” we’ll only see two. Clark Kent has an unpublished article and we have a filter that hides any article with a published_at date in the future. Filters are ignored by facets, however, so to get this working we need to turn the filters into queries. We chose filters over queries as they generally give better performance but for the counting to work we’ll need to use queries instead.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query do boolean do must { string params[:query], default_operator: "AND" } if params[:query].present? must { range :published_at, lte: Time.zone.now } must { term :author_id, params[:author_id] } if params[:author_id].present? end end sort { by :published_at, "desc" } if params[:query].blank? facet "authors" do terms :author_id end end end
We’ve taken the filters we had and merged them the a boolean query. All of the conditions in the must calls need to pass for the query to pass. When we reload the page now we’ll see the correct number of articles displayed for each author.
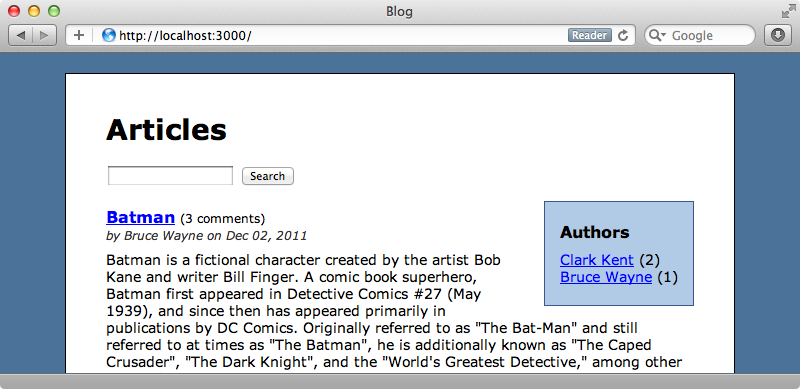
When we select an author the other authors disappear from the list but this is how query facets work.
Debugging
We’ll finish off this episode by showing a couple of methods that help with debugging search queries. The first is to_json and if we call this at the search block level it will give us a string representation of the search that will be sent to Elasticsearch. The other is to_curl which gives us the JSON string along with a curl command that we can run from the command line.
If we add raise to_curl at the end of the search block and reload the page we’ll see the command we need to run.
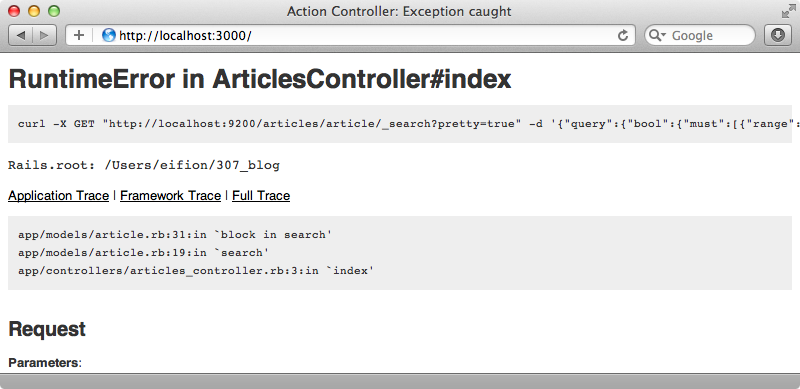
If we run this command in the console we’ll see the JSON response data that would be sent back to Tire from Elasticsearch. This is really useful for debugging when a search isn’t returning the results you’re expecting.
