
#307 ElasticSearch Part 2 pro
- Download:
- source code
- mp4
- m4v
- webm
- ogv
이전 연재에서 Elasticsearch와 Tire gem을 이용해서 레일스 어플리케이션에 풀텍스트 검색기능을 추가하는 방법을 설명했습니다. 여기서 데모로 보여주는 어플리케이션은 글 목록을 보여주고 특정 키워드로 검색할 수 있는 페이지를 제공합니다.
Elasticsearch는 지난 번에 다루지 않았던 더 많은 기능들을 지원하기 때문에 이 연재에서는 지금까지 구현했던 기능을 확장하고 검색 기능을 향상시킬 수 있는 몇가지 기능과 설정 옵션들을 소개할 것입니다.
검색 용어에 따른 검색 기능 재정의하기
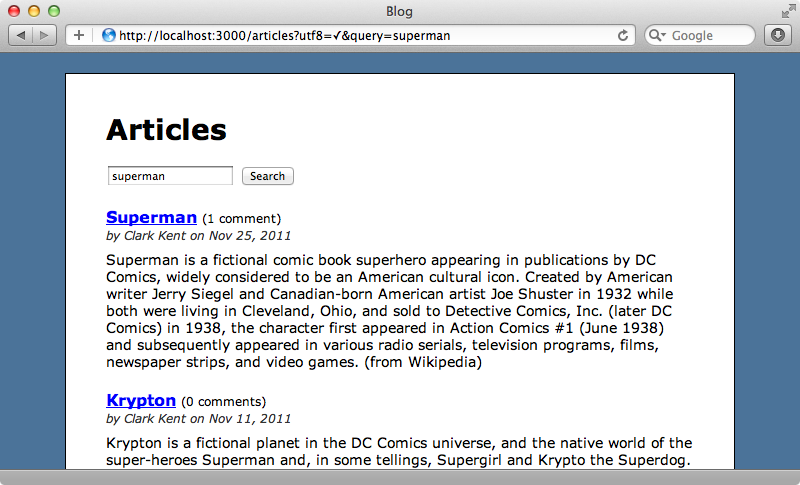
검색창에서 지정할 수 있는 추가 옵션을 설명하면서 시작하도록 하겠습니다. 현재 검색은 superman에 대한 것이고 글 내용 중에 해당 텍스트를 포함하는 글들을 반환하게 됩니다.
글 name이 “Superman”에 일치하는 글을 찾고자한다면, 검색 용어를 name:supermann와 같이 지정할 수 있습니다. 와일드카드 문자를 이용하여 검색을 할 경우에도 이와 비슷하게 “*” 문자를 사용할 수 있습니다. name:*man과 같이 검색할 경우, 글 name이 “man”으로 끝나는 모든 글을 찾아 줄 것입니다. 이 경우에는 Batman과 Superman이 되겠습니다.
문구를 검색하기 위해서는 인용부호를 사용합니다. "fictional character"를 검색할 경우, 해당 문구를 포함하는 글만을 반환할 것입니다. 인용문구 없이 검색할 경우에는 “fictional” 또는 “character”를 포함하는 글만을 반환할 것입니다. fictional OR character와 같이 검색할 경우에도 똑같은 결과를 반환할 것입니다. fictional AND character와 같이 검색할 경우에는 이 두 단어가 모두 포함된 글만을 반환할 것입니다. 마지막으로, fictional NOT character와 같이 검색할 경우에는 “fictional”은 포함하지만 “character”는 포함하지 않는 글만을 반환할 것입니다.
이러한 검색 기능을 변경하는 방법은 다양하게 있습니다. Elasticsearch 가이드의 Query String Query page를 보면 사용할 수 있는 모든 옵션 목록이 있습니다. 그 중의 하나는 default_operator입니다. 이 옵션을 디폴트 값인 OR 대신에 AND로 지정할 경우 검색하는 모든 단어를 포함하는 글만을 반환할 것입니다. 검색을 수행할 Article 모델에서 이와 같이 구현하고자 합니다. 이를 위해서 query 메소드에 default_operator 옵션을 추가해야 합니다.
def self.search(params) tire.search(load: true) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} end end
이제 fictional character로 검색할 경우 두 키워드 모두 일치하는 글만을 반환할 것입니다.
소팅하기
기본적으로는 반환된 글이 관련성에 따라 소팅되지만 search 블록에서 sort 메소드를 사용하여 이와 같은 소팅 순서를 변경할 수 있으며 옵션으로 넘겨 줄 수 있습니다. 물론 소팅 방향으로 옵션을 넘겨 줄 수 있습니다.
def self.search(params) tire.search(load: true) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? end end
이것을 기본 소트로 지정했지만 검색 쿼리문을 입력하지 않은 경우에만 해당합니다. 검색 용어를 입력할 경우 결과는 여전히 관련성에 의해서 소팅될 것입니다.
페이징하기
또 다른 일반적인 요구사항은 페이징 방법이며 검색 메소드에 pagination 옵션을 추가할 수 있습니다.
def self.search(params) tire.search(load: true, page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? end end
page 옵션을 page param 값으로 지정하고 페이지당 2개의 글을 보여주도록 페이징을 지정했습니다. 물론 will_paginate 또는 Kaminari와 같은 페이징 처리를 위한 젬을 추가해야 합니다. gemfile에 will_paginate 젬을 추가하고 bundle 명령을 실행하여 설치할 것입니다.
source 'http://rubygems.org' gem 'rails', '3.1.3' # Bundle edge Rails instead: # gem 'rails', :git => 'git://github.com/rails/rails.git' gem 'sqlite3' # Gems used only for assets and not required # in production environments by default. group :assets do gem 'sass-rails', '~> 3.1.4' gem 'coffee-rails', '~> 3.1.1' gem 'uglifier', '>= 1.0.3' end gem 'jquery-rails' gem 'tire' gem 'will_paginate'
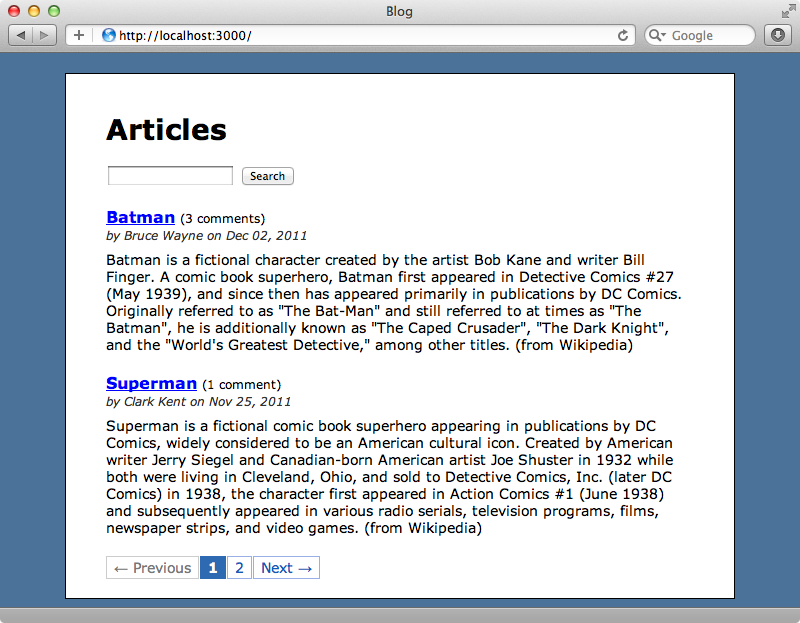
이제 페이지 하단에 will_paginate 메소드를 호출할 수 있습니다.
<%= will_paginate @articles %>이제 페이지를 다시 로드할 경우 두개의 글만을 보게 될 것이고 페이징을 위한 링크들도 보게 될 것입니다. (이미 페이징을 위한 CSS를 추가하였습니다.)
Tire의 DSL에 대해서 간단하게 기술합니다. Tire는 블록을 많이 사용하며 각 블록 내에서 현재의 컨텍스트가 변경됩니다. 이 말은 tire.search 블록 내에서 self는 Article 클래스가 아니고 Tire 검색 객체가 된다는 말입니다. 이 객체는 훌륭한 DSL을 제공해 주어 클래스에 대해서 직접 메소드를 호출할 수 있게 해 주지만 블록 내에서 다른 클래스 메소드를 사용할 때는 혼란을 초래할 수 있습니다. 이런 경우에는 블록에 파라미터를 넘겨 주어 해당 파라미터를 통해서 메소드에 접근할 수 있게 합니다.
def self.search(params) tire.search(load: true, page: params[:page], per_page: 2) do |s| s.query { string params[:query], default_operator: "AND" } if params[:query].present? s.filter :range, published_at: {lte: Time.zone.now} s.sort { by :published_at, "desc" } if params[:query].blank? end end
이와 같이 접근하면 블록 내에서 self는 여전히 Article 클래스를 참조할 수 있는 장점이 있습니다. query와 sort 블록을 포함하여 Tire가 사용하는 대부분의 블록에서 동작하지만 디폴트 문장이 더 깔끔하기 때문에 여기서는 이와 같이 블록에 파라미터를 넘겨 주지 않은채로 코딩을 할 것입니다.
인덱스에 더 많은 필드 추가하기
이제 검색 기능은 어느 정도 완벽해졌으니 인덱싱으로 넘어가도록 하겠습니다. 각 Article의 모든 속성들은 인덱싱이 되어 있지만 Author와 Comment와 같은 관계선언된 모델들의 속성은 그렇지 못합니다. clark에 대한 검색을 하면 이 속성이 인덱싱되어 있지 않기 때문에 반환되는 글이 하나도 없을 것입니다.
이와 같이 관계선언된 속성들을 추가하기 위해서는 해당 모델의 to_indexed_json 메소드를 오버라이드해야 합니다. 이 메소드는 인덱싱할 데이터를 포함하는 JSON 문자열을 반환합니다. 저자명을 추가하기 위해서 to_json을 호출하여 포함하고자는 하는 추가 데이터를 넘겨줍니다. 저자명을 포함하기 위해서 호출할 메소드 배열과 함께 methods를 호출합니다. 여기서 author_name를 정의해서 해당 글의 저자명을 반환하도록 해야 합니다.
def to_indexed_json to_json(methods: [:author_name]) end def author_name author.name end
데모 어플리케이션에서는 레일스 3.1을 사용하기 때문에, to_json이 글의 속성들을 직열화(serialize)하듯이, 위의 코드는 완벽하게 동일하게 동작할 것이고, 이 경우에는 관계선언된 저자명을 포함하게 됩니다. 레일스의 이전 버전에서는 루트 요소를 포함하지만 해당 모델에 아래의 코드라인을 추가하여 이 루트 요소를 제거할 수 있습니다.
self.include_root_in_json = false
지금까지 변경한 내용을 반영하기 위해서 레코드를 리인덱싱해야 하는데 Tire는 이를 위해서 Rake task를 제공합니다. 이 task에는 리인덱싱하고자 하는 클래스 이름이 필요하고 기존 인덱스를 리빌드할 때는 FORCE 인수를 넘겨 주어야 합니다. Article 클래스는 레일스 환경 내에 있기 때문에 해당 환경을 로드해야 할 필요가 있어서 environment task를 인수들 앞에 두어야 합니다.
$ rake environment tire:import CLASS=Article FORCE=true
[IMPORT] Deleting index 'articles'
[IMPORT] Creating index 'articles' with mapping:
{"article":{"properties":{}}}
[IMPORT] Starting import for the 'Article' class
--------------------------------------------------------------------------------
4/4 | 100% ###########################################################
================================================================================
Import finished in 0.36422 seconds이 task는 페이징이 필요한데 페이징 메소드가 정의되어 있지 않다는 에러를 보게 될 경우 실행 전에 어플리케이션의 gemfile에 will_paginate나 Kaminari 젬을 추가해야 할 것입니다. 이제 글을 리인덱싱했기 때문에 저자명을 검색할 수 있고 일치하는 글들이 반환되는 것을 보게 될 것입니다.
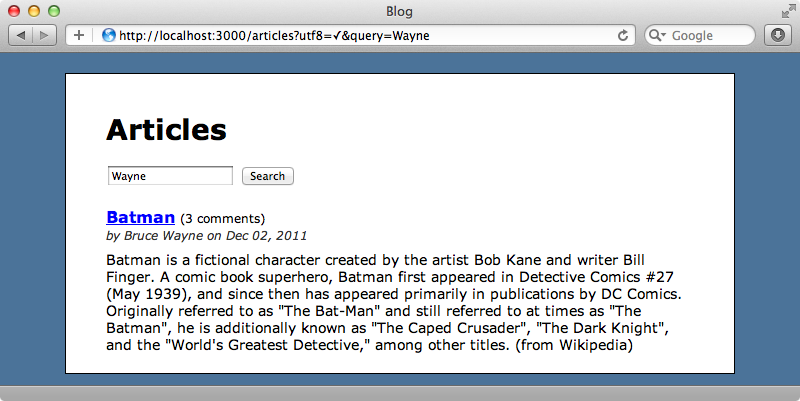
인덱스로부터 모든 데이터를 가져오기
Article 모델에서 검색을 할 때 load: true 옵션을 넘겨 줍니다. 이것은 인덱스의 속성을 사용하는 대신 데이터베이스로부터 직접 일치하는 글을 로드하라는 의미입니다. 이전 연재에서는 글들을 나타내기 위해서 필요한 모든 속성을 인덱싱하지 않았기 때문에 이 옵션을 지정해야만 했습니다. 인덱스에 이 속성들을 추가했었다면 이 옵션은 필요없게 되고 이로 인해 데이터베이스로부터 레코드를 로드할 필요가 없어지기 때문에 퍼포먼스가 더 좋아질 것입니다.
이를 구현하기 위해서 관계선언으로부터 데이터를 나타내는 모든 것을 뷰로부터 제거해야 합니다. 예를 들어, 저자명을 나타내기 위해서 article.author.name을 호출하고 댓글수를 나타내기 위해서 article.comments.size를 호출합니다. Article로부터 이것들을 메소드로 대체해서 인덱스로부터 쉽게 가져올 수 있도록 할 수 있습니다. 이미 author_name 메소드를 정의해 놓았고 다음으로 댓글수를 반환하는 comment_count 메소드를 작성할 것입니다.
<div id="articles"> <% @articles.each do |article| %> <h2> <%= link_to article.name, article %> <span class="comments">(<%= pluralize(article.comment_count, 'comment') %>)</span> </h2> <div class="info"> by <%= article.author_name %> on <%= article.published_at.strftime('%b %d, %Y') %> </div> <div class="content"><%= article.content %></div> <% end %> </div>
다음으로 모델에 이 메소드를 추가해서 인덱스로 추가할 것입니다.
def to_indexed_json to_json(methods: [:author_name, :comment_count]) end def author_name author.name end def comment_count comments.size end
인덱스를 변경했기 때문에 이전에 실행했던 명령을 이용해서 인덱스를 다시 빌드해야 할 것입니다.
$ rake environment tire:import CLASS=Article FORCE=true
이제 페이지에 나타낼 모든 속성을 인덱스에 저장할 것이기 때문에 데이터베이스로부터 글을 로드하는 load: true 옵션을 제거할 수 있습니다.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? end end
이와 같이 변경을 했으므로 이제 글이 제대로 페이지에 보이게 될까요? 그렇지 않습니다. 기대하는 글 목록 대신에 “undefined strftime method” 예외가 발생하게 됩니다.
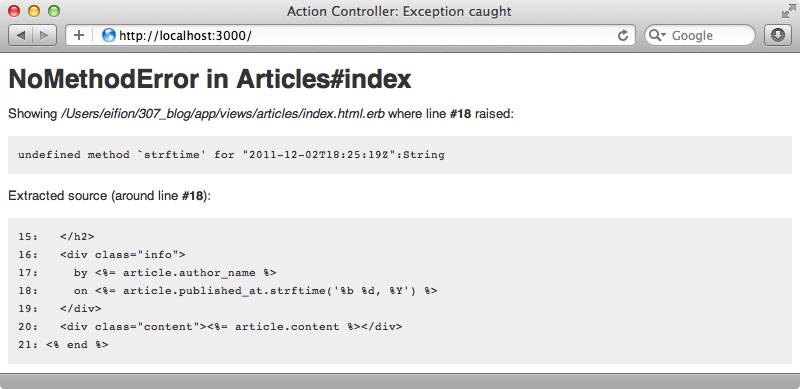
각 글의 published_at 속성은 DateTime 데이터형 대신에 인덱스에 문자열로 저장되어 문자열에 대해서 strftime 메소드를 호출할 수 없게 됩니다. 이러한 오류를 바로 잡기 위해서 strftime을 호출하기 전에 이 속성에 대해서 to_time을 호출해야 합니다.
<div class="info"> by <%= article.author_name %> on <%= article.published_at.to_time.strftime('%b %d, %Y') %> </div>
이제 페이지를 다시 로드하면 제대로 동작하게 되고 데이터베이스로부터가 아니라 인덱스로부터 모든 데이터를 가져오게 됩니다.
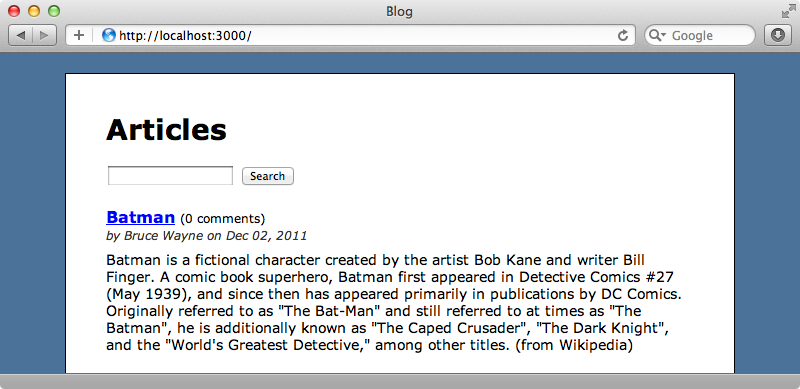
심지여 Tire는 레코드를 전적으로 Elasticsearch에 저장할 수 있게 해 주는 모듈을 제공해 줍니다. Tire의 README 파일 하단에 이것을 구현하는 방법에 대해서 자세히 설명되어 있습니다.
커스텀 매핑 사용하기
Elasticsearch에서 속성들을 인덱싱하는 방법을 좀 더 세밀하게 제어해야할 때가 있습니다. 현재로서는 Elasticsearch에게 단순한 JSON 문자열를 넘겨 주기만 하는데 대개 별문제 없이 잘 동작합니다. 그러나 좀 더 세밀하게 조절해야할 필요성이 있을 때는 매핑을 작성하는 것이 최선의 방법입니다. 모델에서 mapping을 호출하여 이러한 작업을 할 수 있습니다. 이것은 블록을 넘겨 받아 블록내에서 indexes를 사용하여 인덱싱하고자 하는 속성들을 정의합니다.
class Article < ActiveRecord::Base belongs_to :author has_many :comments include Tire::Model::Search include Tire::Model::Callbacks mapping do indexes :id, :type: 'integer' indexes :author_id, type: 'integer' indexes :author_name indexes :name, boost: 10 indexes :content indexes :published_at, type: 'date' indexes :comment_count, type: 'integer' end # Rest of class omitted end
기본 데이터형은 문자열이지만 type 옵션을 사용하여 데이터형을 변경할 수 있습니다. 여기서 사용할 수 있는 다른 옵션이 있는데 name 속성에 대해서 boost 옵션을 사용해서 name 속성의 우선 순위를 높게 했습니다. 이것의 기본값은 1이지만 이 값을 더 높게 지정할 경우 다른 속성에 동일한 검색 키워드가 발견되는 경우보다 해당 속성에서 동일한 키워드가 발견될 때 더 놓은 연관성을 주게 될 것입니다.
또한 analyzer 옵션을 사용할 수 있습니다. 이 옵션은 텍스트가 인덱싱되는 방법을 변경하는데 analyzer별로 단어를 다르게 분리하거나 대소문자 처리방법을 달리할 수 있습니다. Analyzer는 이 연재의 영역을 벗어나는 것이지만 필요시에 이러한 옵션을 사용할 수 있다는 것을 알아두는 것이 좋을 것입니다.
인덱스로 넘길 수 있는 옵션에 대한 더 자세한 정보를 원할 경우 문서상에서 Core Types page를 찾아보기 바랍니다. 또한 문서상에서 Analyzer에 관한 더 자세한 정보를 참고할 수 있습니다.
인덱스 매핑을 정의했기 때문에 다시 데이터를 리인덱싱해야 합니다.
$ rake environment tire:import CLASS=Article FORCE=true
[IMPORT] Deleting index 'articles'
[IMPORT] Creating index 'articles' with mapping:
{"article":{"properties":{"id":{"type":"integer"},"author_id":{"type":"integer"},"author_name":{"type":"string"},"name":{"boost":10,"type":"string"},"content":{"type":"string"},"published_at":{"type":"date"},"comment_count":{"type":"integer"}}}}
[IMPORT] Starting import for the 'Article' class
--------------------------------------------------------------------------------
4/4 | 100% ###########################################################
================================================================================
Import finished in 0.23757 seconds주목할 것은 이번에는 데이터가 리인덱싱됨에 따라 매핑에 대한 자세한 내용을 보게 된다는 것입니다.
Facets
이제 새로운 인덱스가 셋업되었으므로 facet 검색 기능을 추가할 것입니다. 저자 목록을 링크로 페이지에 추가하면 사용자는 특정 저자를 클릭하여 검색 결과를 필터할 수 있을 것입니다. facet을 추가하기 위해서는, 모델의 search 블록에서 facet을 호출하여 코드를 변경해야 합니다.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} sort { by :published_at, "desc" } if params[:query].blank? facet "authors" do terms :author_id end end end
facet에 이름을 지정하고 블록을 넘겨 주어야 합니다. 블록 내에서 author_id 속성에 대한 terms라는 facet을 셋업합니다. 뷰에서 facet을 나타내기 위해서는 아래의 코드를 추가할 수 있습니다.
<div id="facets"> <h3>Authors</h3> <ul> <% @articles.facets['authors']['terms'].each do |facet| %> <li> <%= link_to_unless_current Author.find(facet['term']).name, params.merge(author_id: facet['term']) %> <% if params[:author_id] == facet['term'].to_s %> (<%= link_to "remove", author_id: nil %>) <% else %> (<%= facet['count'] %>) <% end %> </li> <% end %> </ul> </div>
위의 코드에서는 사용자가 글을 저자별로 필터할 수 있는 저자의 목록을 나타냅니다. @article.facets을 호출하고 모델의 facet 이름을 사용하여 각 facet를 불러오기 위해서 ['terms']를 호출한 후 저자 목록을 불러 옵니다. 현재 선택된 저자들은 제외하고 각 저자에 대한 링크를 생성합니다. facet['term']를 호출하여 각 저자의 id 값을 얻을 수 있으며 이를 이용해서 각 저자를 가져온 후 링크를 걸어 저자명을 나타낼 수 있습니다.
author_id 파라미터가 존재하고 해당 저자로 필터된 글들이 존재할 경우 해당 저자에 대해 “remove” 링크를 추가할 것입니다. 다른 저자들에 대해서는 해당 저자가 작성한 글의 갯수를 보여 줄 것입니다.
아래에서 페이지에 새로 추가된 부분을 볼 수 있습니다. 이미 이쁘게 보이도록 약간의 CSS를 추가했습니다.
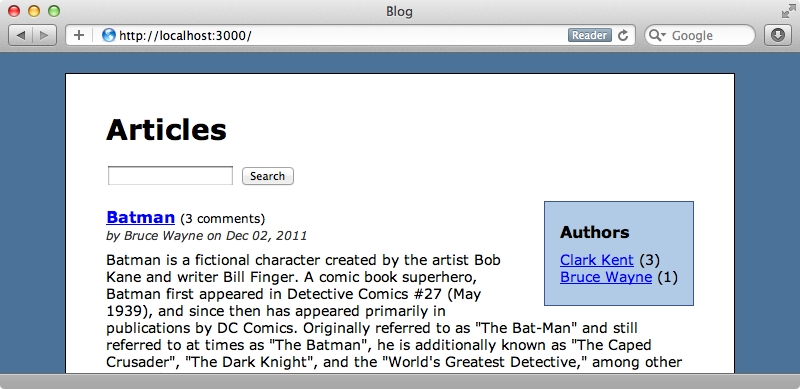
저자 이름 중의 하나를 선택할 경우 해당 저자들이 작성한 글만이 필터되어 보일 것입니다. 선택한 저자 이름 옆에 있는 “remove” 링크를 클릭하면 해당 필터를 제거할 수 있습니다.
이와 같이 선택한 저자를 감안하기 위해서는 검색을 셋업해야 합니다. 이를 위해서 search 블록에 필터를 추가합니다.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query { string params[:query], default_operator: "AND" } if params[:query].present? filter :range, published_at: {lte: Time.zone.now} filter :term, author_id: params[:author_id] if params[:author_id].present? sort { by :published_at, "desc" } if params[:query].blank? facet "authors" do terms :author_id end end end
이 필터는 term 필터이며 params에 존재할 경우 author_id로 글을 필터하게 됩니다. 이제 페이지를 다시 로드한 후 특정 저자를 선택하면 해당 저자가 작성한 글들만이 필터되어 보여질 것입니다.
그러나 여기에는 약간의 문제가 있습니다. 선택한 저자가 없는 경우, 저자 목록이 보여지는 패널에는 Clark Kent가 작성한 글이 세 개 존재하게 됩니다. 그러나 “Clark Kent”를 클릭할 때 두 개만 보이게 될 것입니다. Clark Kent는 아직 게재하지 않은 글을 하나 가지고 있고 published_at 날짜 값을 가지는 않는 글은 감추도록 하는 필터가 적용되어 있습니다. 그러나 facet은 필터를 무시하기 때문에 이러한 문제를 해결하기 위해서 필터를 쿼리로 변경해야 합니다. 일반적으로 퍼포먼스가 더 좋기 때문에 쿼리보다는 필터를 선택했던 것이지만 글의 갯수 연산이 제대로 동작하기 위해서는 쿼리를 대신 사용해야 할 것입니다.
def self.search(params) tire.search(page: params[:page], per_page: 2) do query do boolean do must { string params[:query], default_operator: "AND" } if params[:query].present? must { range :published_at, lte: Time.zone.now } must { term :author_id, params[:author_id] } if params[:author_id].present? end end sort { by :published_at, "desc" } if params[:query].blank? facet "authors" do terms :author_id end end end
필터를 모두 boolean 쿼리로 머지했습니다. must 호출시에 적용되는 모든 조건들이 쿼리를 만족해야 합니다. 이제 페이지를 다시 로드하면 각 저자가 작성한 글의 갯수가 정확하게 표시되는 것을 보게 될 것입니다.
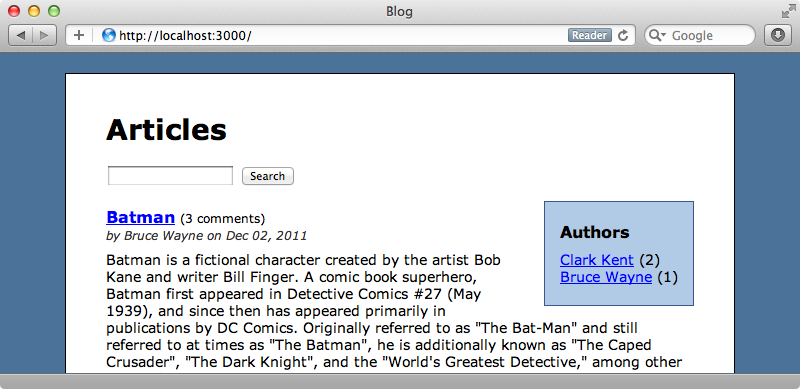
특정 저자를 선택하면 다른 저자들은 목록에서 보이지 않게 되지만 이것은 쿼리 facet이 동작하는 방식입니다.
디더깅하기
이제 검색 쿼리를 디버깅하는 것을 도와주는 몇가지 메소드를 소개하고 이 연재를 마치도록 하겠습니다. 첫번째는 to_json 메소드인데 search 블록 레벨에서 이 메소드를 호출할 경우 Elasticsearch로 넘어가는 검색 문자열을 볼 수 있게 됩니다. 다른 것은 to_curl 메소드인데 커맨드라인에서 실행할 수 있는 curl 명령과 함께 JSON 문자열을 반환해 줍니다.
search 블록 끝에 raise to_curl 코드라인을 추가하고 페이지를 다시 로드하면 실행하게 될 명령을 보게 될 것입니다.
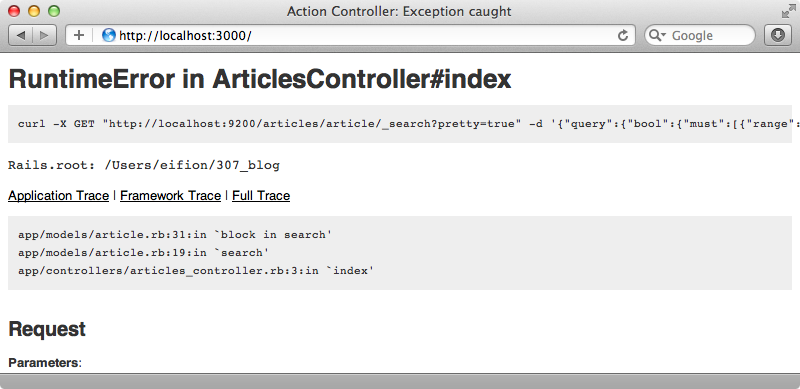
콘솔에서 이 명령을 실행하면 Elasticsearch로부터 Tire로 보내지는 JSON 응답 데이터를 보게 될 것입니다. 이것은 검색시 원하는 결과를 얻지 못할 때 디버깅을 위해 매우 유용하게 사용될 수 있습니다.
