That would put the cache files as "/products/true" and "/products/false". Granted not the best of names, but what do we care what the cache files are named under the hood? ;-)
Although after seeing this railscast, there are some features (:cache_path) that didn't exist when I first wrote it, so I think I'll be making another update of the plugin soon to make use of it. :)
First off Ryan thank you so much for all your railscasts. They have been invaluable in my learning process. Now I'm wondering if action caching will work with pagination. I tried a couple of different things but I can't seem to get it to work. I was just wondering before I go to a lot of recoding on my existing blog to add this.
I notice that :cache_path removes the name of the host if a string is returned.
Without :cache_path the fragment may be called "localhost:3000/foobar", but if you specify :cache_path => "/foobar", the fragment is written as just "/foobar" without the host which is a big difference.
Using the to_proc technique explained here returning a string is basically the same as using just a string, so you'll lose the hostname in the fragement as well.
So if you depend on the host in the written fragment, you'll have to include the hostname in your string.
@Brad, the plugin I was referring to is called Action Cache. However I'm not entirely sure if it works with Rails 2.0, there are alternative solutions as Andrew mentioned.
http://wiki.rubyonrails.org/rails/pages/Action+Cache+Update+Plugin
@Ted, yep, that should work. I prefer the more descriptive names but to each his own. :)
@Mitchell, in order to get this to work with pagination you'll need to include the page number in the name of the cache. You can use the dynamic technique as shown at the end of this episode to put the params[:page] value in the name of the cache and it should work.
@Andrew, you're right, the domain name gets chopped when passing a string as the path. This behaves the same in fragment caching as well. I can see how either behavior could be desirable. If you do want the domain with the port in the path then you can include that in the string.
@Wallen, as far as I know there's no "if" option. So if you want to disable caching entirely you should look into a plugin as mentioned above. Actually, I've never tried returning nil for the cache path so that might work too.
I really do not understand. I'm in the case of Mitchell Blankenship. Ok to named paginated pages path dynamically but how to destroy them with the sweeper ? The great way expire_fragment (% r (pages / \ d * /) notes) does not work with expire_action! It's unbelievable! I found this example that seems to work but it is inconceivable! http://www.fngtps.com/2006/01/lazy-sweeping-the-rails-page-cache You have a better method ?
Those looking for the pagination code, I used this and it seems to work (using restful authentication for the login info):
def index_cache_path
if logged_in? && current_user.has_role?('administrator')
"/admin/questions/#{params[:page]}"
else
"/public/questions/#{params[:page]}"
end
end
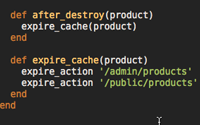
I figured out how to get paginated pages to cache, but I'm having trouble getting them to expire:
def expire_cache(question)
expire_action "public/questions/"
end
The index page (page 1) expires properly, but all other pages do not - they cache once and never expire.
I've tried putting * at the end of that path and also including the #{params[:page} at the end of the path (I don't think this should work though since that isn't passed). How can you erase the cache for an entire directory?
So after a lot of research I've figured out how to do this somewhat properly. Short answer is:
def expire_cache(question)
expire_fragment(%r{public/questions.*})
end
Here's the explanation:
1. You can't use expire_action, you need to use expire_fragment
2. You need to use a regex
So if you take a look at the source for expire_action and expire_fragment you'll notice that expire_fragment has a "key" passed to it and expire_action does not accept one:
You'll also notice that expire_action is largely just a proxy to expire_fragment if all you're doing is passing it an actual path.
You'll probably want to craft your regex much more elegantly and safely than I have done here, especially if you are caching more than just one thing.
In the end though I see it as an issue with the rails code and expire_action should take the regex as an argument just like expire_fragment does I think.
def index_cache_path
p = ''
p = params[:page] if params[:page] and params[:page] != 1
if logged_in? and current_user.has_role?('super user')
'/admin/people' + p
elsif logged_in?
'/private/people' + p
else
'/public/people' + p
end
end
My problem is that some of my cached index actions respond to an XML format for RSS feeds, but they are unreachable because the action is cached. Is there a way in my index_cache_path to check if a request was XML so I can append 'xml' to the returned cache path?
Ryan, you are a star. I've been fiddling about with the :layout => false option for a while trying to achieve this however it fails when using content_for, this solution is ideal... Thanks!!

Got a link to that caching plugin you were talking about?
Hey Ryan, I'm wondering if it could have been a little more clever and used string replacement like this:
caches_action :index, :cache_path => Proc.new{ "/products/#{admin?}" }
That would put the cache files as "/products/true" and "/products/false". Granted not the best of names, but what do we care what the cache files are named under the hood? ;-)
I have a plugin called conditional caching that I wrote years ago, and is still maintained.
http://agilewebdevelopment.com/plugins/conditional_caching
Although after seeing this railscast, there are some features (:cache_path) that didn't exist when I first wrote it, so I think I'll be making another update of the plugin soon to make use of it. :)
First off Ryan thank you so much for all your railscasts. They have been invaluable in my learning process. Now I'm wondering if action caching will work with pagination. I tried a couple of different things but I can't seem to get it to work. I was just wondering before I go to a lot of recoding on my existing blog to add this.
I notice that :cache_path removes the name of the host if a string is returned.
Without :cache_path the fragment may be called "localhost:3000/foobar", but if you specify :cache_path => "/foobar", the fragment is written as just "/foobar" without the host which is a big difference.
Using the to_proc technique explained here returning a string is basically the same as using just a string, so you'll lose the hostname in the fragement as well.
So if you depend on the host in the written fragment, you'll have to include the hostname in your string.
Sorry for the delayed response everyone.
@Brad, the plugin I was referring to is called Action Cache. However I'm not entirely sure if it works with Rails 2.0, there are alternative solutions as Andrew mentioned.
http://wiki.rubyonrails.org/rails/pages/Action+Cache+Update+Plugin
@Ted, yep, that should work. I prefer the more descriptive names but to each his own. :)
@Mitchell, in order to get this to work with pagination you'll need to include the page number in the name of the cache. You can use the dynamic technique as shown at the end of this episode to put the params[:page] value in the name of the cache and it should work.
@Andrew, you're right, the domain name gets chopped when passing a string as the path. This behaves the same in fragment caching as well. I can see how either behavior could be desirable. If you do want the domain with the port in the path then you can include that in the string.
Excellent tutorial! I did not feel cheated ;).
Why bother caching the admin page? Is it not possible to cache_action :if ?
@Wallen, as far as I know there's no "if" option. So if you want to disable caching entirely you should look into a plugin as mentioned above. Actually, I've never tried returning nil for the cache path so that might work too.
Great episode! I liked the twist :)
Ryan, thanks for the great screencasts. Does the :cache_path work for Rails 1.2.6? My proc never seems to get called.
I am caching a lot of actions and some with ids. I was caching them under different folders. My get path uses this string to return:
"/#{params[:controller]/params[:action]"
There is another version with the id tacked on. But expire_action is not removing any of the caches. My call in foo_sweeper looks like this.
expire_action "/foo"
any ideas?
Thanks
I really do not understand. I'm in the case of Mitchell Blankenship. Ok to named paginated pages path dynamically but how to destroy them with the sweeper ? The great way expire_fragment (% r (pages / \ d * /) notes) does not work with expire_action! It's unbelievable! I found this example that seems to work but it is inconceivable! http://www.fngtps.com/2006/01/lazy-sweeping-the-rails-page-cache You have a better method ?
Those looking for the pagination code, I used this and it seems to work (using restful authentication for the login info):
def index_cache_path
if logged_in? && current_user.has_role?('administrator')
"/admin/questions/#{params[:page]}"
else
"/public/questions/#{params[:page]}"
end
end
Hey Ryan -
I figured out how to get paginated pages to cache, but I'm having trouble getting them to expire:
def expire_cache(question)
expire_action "public/questions/"
end
The index page (page 1) expires properly, but all other pages do not - they cache once and never expire.
I've tried putting * at the end of that path and also including the #{params[:page} at the end of the path (I don't think this should work though since that isn't passed). How can you erase the cache for an entire directory?
==How to expire paginated pages
So after a lot of research I've figured out how to do this somewhat properly. Short answer is:
def expire_cache(question)
expire_fragment(%r{public/questions.*})
end
Here's the explanation:
1. You can't use expire_action, you need to use expire_fragment
2. You need to use a regex
So if you take a look at the source for expire_action and expire_fragment you'll notice that expire_fragment has a "key" passed to it and expire_action does not accept one:
http://api.rubyonrails.org/classes/ActionController/Caching/Fragments.html
http://api.rubyonrails.org/classes/ActionController/Caching/Actions.html
You'll also notice that expire_action is largely just a proxy to expire_fragment if all you're doing is passing it an actual path.
You'll probably want to craft your regex much more elegantly and safely than I have done here, especially if you are caching more than just one thing.
In the end though I see it as an issue with the rails code and expire_action should take the regex as an argument just like expire_fragment does I think.
@jc Thank you for this very interesting explanation. This may be a good alternative to the FileUtils.
For pagination I use:
def index_cache_path
p = ''
p = params[:page] if params[:page] and params[:page] != 1
if logged_in? and current_user.has_role?('super user')
'/admin/people' + p
elsif logged_in?
'/private/people' + p
else
'/public/people' + p
end
end
My problem is that some of my cached index actions respond to an XML format for RSS feeds, but they are unreachable because the action is cached. Is there a way in my index_cache_path to check if a request was XML so I can append 'xml' to the returned cache path?
Ryan, you are a star. I've been fiddling about with the :layout => false option for a while trying to achieve this however it fails when using content_for, this solution is ideal... Thanks!!
@jc Looks like the Regex approach only works for non-memcached solutions. For those using memcache, it sounds like a versioning approach would work best: http://stackoverflow.com/questions/9283141/expiring-cache-key-path-trees-for-resources