
#343 Full-Text Search in PostgreSQL pro
- Download:
- source code
- mp4
- m4v
- webm
- ogv
In past episodes we’ve covered many solutions for full-text searching, including Thinking Sphinx, Sunspot and ElasticSearch. All of these require an external search engine, separate from the database but if we use Postgres for our application’s database we can take advantage of its built-in full-text search capability. There are many advantages to keeping the full-text search inside the primary database and we’ll mention some of these as we show you how this works in this episode. The application will be working with in this episode is a simple blogging application that shows a number of articles. We’ve already implemented some of this application’s features, including pagination and a simple search form, similar to the one we demonstrated in episode 37, that finds articles whose name or content contains the search term.
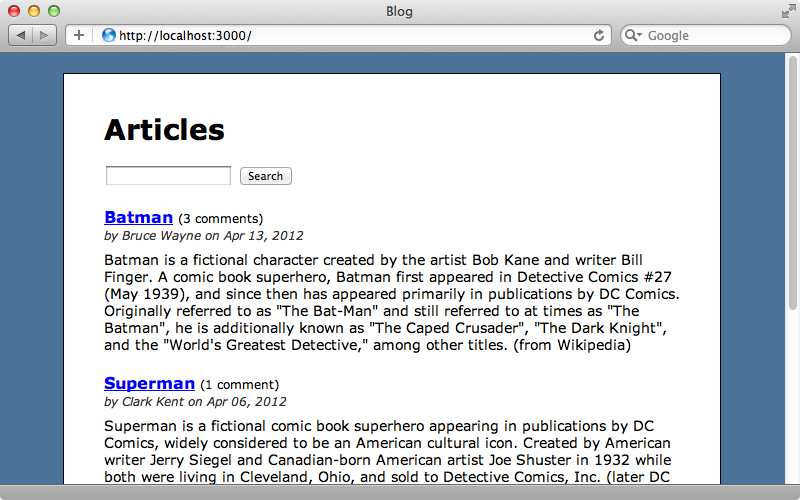
First we’ll walk through the source code for this application, starting with the view template for the page above.
<h1>Articles</h1> <%= form_tag articles_path, method: :get do %> <p> <%= text_field_tag :query, params[:query] %> <%= submit_tag "Search", name: nil %> </p> <% end %> <div id="articles"> <% @articles.each do |article| %> <h2> <%= link_to article.name, article %> <span class="comments">(<%= pluralize(article.comments.size, 'comment') %>)</span> </h2> <div class="info"> by <%= article.author.name %> on <%= article.published_at.strftime('%b %d, %Y') %> </div> <div class="content"><%= article.content %></div> <% end %> </div> <%= will_paginate @articles %>
This template contains the code that renders the list of articles and also the simple search form. When the form is submitted the search term is passed as query parameter to the articles path, which is the ArticlesController’s index action. Let’s look at that next.
def index @articles = Article.text_search(params[:query]).page(params[:page]).per_page(3) end
Here we fetch the articles we want by calling a custom text_search class method on the Article model and passing the query parameter to it, along with the current page number and number of articles per page. The text_search method looks like this:
def self.text_search(query) if query.present? where("name ilike :q or content ilike :q", q: "%#{query}%") else scoped end end
Here we check to see if the query parameter is present and if it is we find the articles that match that query using a like comparison (actually ilike so that the search is case-insensitive). We compare the articles’ name and content columns to the query, which is wrapped in percent signs so that the search term is matched anywhere in those fields.
Using Full-Text Searching
This is a poor excuse for full-text searching so let’s take advantage of Postgres’s full-text search feature to improve it. One problem with our current approach is that we’re treating the search term as a single string so if we search for “superman character” no articles are returned even though we have articles that contain both those words but not together. Changing from a like condition to a full-text search with Postgres is quite easy. All we have to do is replace ilike with double at signs (@@) and remove the percent signs from the search term like this:
def self.text_search(query) if query.present? where("name @@ :q or content @@ :q", q: query) else scoped end end
When we search for “superman character” now we’ll see all the articles that contain both of those words.
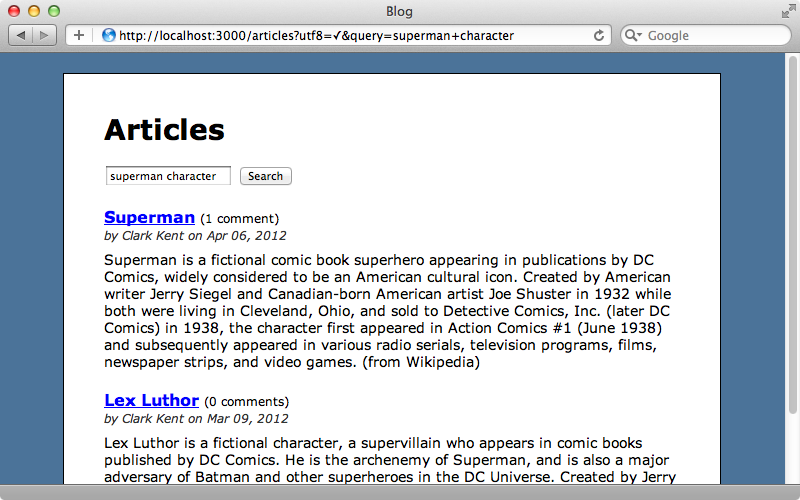
By default the full-text search uses an English dictionary with stemming so if we search for “superman characters” (note the extra “s”) we get the same set of results, even though the word “characters” isn’t in the articles. Stop words are also supported which means that common English words will be ignored. If we search for “superman of dc comics”, this will return the “Superman” article even though it doesn’t contain the word “of”.
One of the best reasons for keeping full-text searching in the database is that it works seamlessly with all other SQL clauses. For example our pagination still works without any adjustment from us. The text_search method is still just a simple ActiveRecord scope that we can add other clauses to, such as page and per_page for pagination. Another good reason for using this approach is that everything stays in sync automatically: if we were to create a new article, or edit an article, that content is instantly available in the full-text search.
How Full-Text Searching Works
We’ve shown how powerful full-text searching is but what’s going on when we use it and how can we get the most from it? We’ll use the database console to show what goes on when we make a full-text search. We can use the rails db command to enter the Postgres console and we’ll use the SELECT command with some static text to experiment with various operators and functions.
noonoo:blog eifion$ rails db psql (9.1.2) Type "help" for help. blog_development=# select 'ninja turtles' @@ 'turtles'; ?column? ---------- t (1 row)
The t we get as a response stands for true. Searching for turtle here will return true as well because of stemming, while searching for something else entirely such as green will return false. There’s some typecasting going on behind the scenes here. The phrase on the left side of the @@ is being converted to a tsvector while the phrase on the right is converted to a plain tsquery. We can mimic this by calling the relevant functions.
blog_development=# select to_tsvector('ninja turtles') @@ plainto_tsquery('turtle');
?column?
----------
t
(1 row)This isn’t the full story, however. We can pass a dictionary as a first argument to these functions, like this:
blog_development=# select to_tsvector('english', 'ninja turtles') @@ plainto_tsquery('english', 'turtle');
?column?
----------
t
(1 row)English is the default dictionary so this will give us the same results as before. This means that we can change the language or do a more literal search by passing in simple instead of english.
blog_development=# select to_tsvector('simple', 'ninja turtles') @@ plainto_tsquery('simple', 'turtle');
?column?
----------
f
(1 row)This time we get a false response as we’re searching for turtle not turtles.
You might be wondering what the difference between a plain tsquery and a normal one is. If we use to_tsquery instead of plainto_tsquery we’ll get the same results as we only have a single word in our query. If we enter multiple search words, though, we’ll get a syntax error.
blog_development=# select to_tsvector('simple', 'ninja turtles') @@ to_tsquery('simple', 'ninja turtles');
ERROR: syntax error in tsquery: "ninja turtles"A normal tsquery expects boolean operators between each word so we can use & to search for ninja and turtles or a pipe to search for ninja or turtles.
blog_development=# select to_tsvector('simple', 'ninja turtles') @@ to_tsquery('simple', 'ninja | turtles');
?column?
----------
t
(1 row)To exclude a word we use an exclamation mark, so ninja & !turtles would match text that contains ninja but not turtles. If we’re going to use a plain to_tsquery like this we’ll need to translate whatever the user enters as a search term and use the relevant operators.
When performing a plain-text search we often want to sort the results by relevance. We can do this by using the ts_rank function which returns a float value that we can use for ranking.
blog_development=# select ts_rank(to_tsvector('ninja turtles'), to_tsquery('turtles'));
ts_rank
-----------
0.0607927
(1 row)Now that we know how to sort by relevance let’s apply this to our application. We’ll add some code to the text_search method in the Article model that sets a rank variable to the value of the sum of the ranks for the name and content fields. We can then order the results by that rank in descending order.
def self.text_search(query) if query.present? rank = <<-RANK ts_rank(to_tsvector(name), plainto_tsquery(#{sanitize(query)})) + ts_rank(to_tsvector(content), plainto_tsquery(#{sanitize(query)})) RANK where("name @@ :q or content @@ :q", q: "%#{query}%").order("#{rank} desc") else scoped end end
When we search for “dc comics” now the Superman article will appear at the top of the results as that’s the article that contains that phrase most frequently.
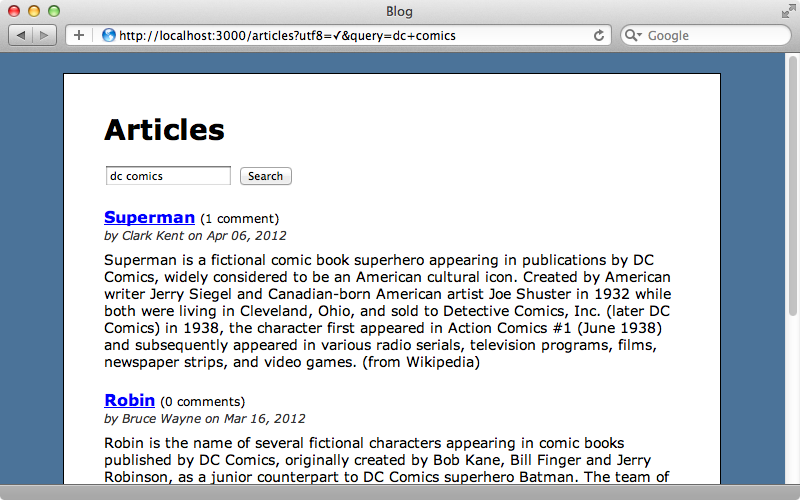
Texticle and PgSearch
The text_search method is starting to get a little messy and it will only get worse if we search against more columns. Fortunately there’s a gem that can help up here. Texticle makes it easier to do full-text searching in Postgres. To use it we just need to add it to the application’s gemfile and then run bundle to install it.
gem 'texticle', require: 'texticle/rails'
Now we can clean up the text_search method in our model like this:
def self.text_search(query) if query.present? search(query) else scoped end end
This will automatically search all text-based columns on the table and do much the same as we had before. If we search for “Superman” again now and look at the log file we’ll see the SQL query that was made.
Article Load (2.5ms) SELECT "articles".*, ts_rank(to_tsvector('english', "articles"."name"::text), to_tsquery('english', 'dc\ comics'::text)) + ts_rank(to_tsvector('english', "articles"."content"::text), to_tsquery('english', 'dc\ comics'::text)) AS "rank0.9491099641574605" FROM "articles" WHERE (to_tsvector('english', "articles"."name"::text) @@ to_tsquery('english', 'dc\ comics'::text) OR to_tsvector('english', "articles"."content"::text) @@ to_tsquery('english', 'dc\ comics'::text)) ORDER BY "rank0.9491099641574605" DESC LIMIT 3 OFFSET 0
(1.2ms) SELECT COUNT(*) FROM "articles" WHERE (to_tsvector('english', "articles"."name"::text) @@ to_tsquery('english', 'dc\ comics'::text) OR to_tsvector('english', "articles"."content"::text) @@ to_tsquery('english', 'dc\ comics'::text))This query is similar to the manual one we had, using ts_rank to generate a rank and @@ to compare a tsvector and a tsquery.
Texticle is great for a simple full-text search like this but if we want a more customizable solution then another gem called PgSearch is better. This offers a couple of ways to do full-text searching in Postgres. One option called multi-search will search multiple models at once. The other option is called pg_search_scope and is used for searching a single model. We’ll use this second option in our application. First we’ll replace the texticle gem in our gemfile with pg_search and then run bundle again to install it.
#gem 'texticle', require: 'texticle/rails' gem 'pg_search'
Now in our Article model we need to include PgSearch. We can then use the pg_search_scope method. We need to pass in a name for our scope and we’ll call ours search. We can then use the against option to specify the columns that we want to search. This will generate a search method which we can use in the same way we used it with Texticle.
class Article < ActiveRecord::Base attr_accessible :author_id, :author, :content, :name, :published_at belongs_to :author has_many :comments include PgSearch pg_search_scope :search, against: [:name, :content] def self.text_search(query) if query.present? search(query) else scoped end end end
We’ll need to restart our Rails application for these changes to be picked up but after we do we should have full-text searching working with PgSearch. This won’t work exactly as before as it doesn’t use the English dictionary by default so if we search for “characters” the articles containing “character” won’t be returned. If we look at the log we’ll see that query passes simple to the tsvector and tsquery instead of the English dictionary.
Article Load (1.5ms) SELECT "articles".*, (ts_rank((to_tsvector('simple', coalesce("articles"."name", '')) || to_tsvector('simple', coalesce("articles"."content", ''))), (to_tsquery('simple', ''' ' || 'characters' || ' ''')), 0)) AS pg_search_rank FROM "articles" WHERE (((to_tsvector('simple', coalesce("articles"."name", '')) || to_tsvector('simple', coalesce("articles"."content", ''))) @@ (to_tsquery('simple', ''' ' || 'characters' || ' ''')))) ORDER BY pg_search_rank DESC, "articles"."id" ASC LIMIT 3 OFFSET 0To get this behaviour back we’ll need to specify the dictionary like this:
pg_search_scope :search, against: [:name, :content], using: {tsearch: {dictionary: "english"}}
Now when we search for “characters” we’ll get the articles that contain “character” returned too.
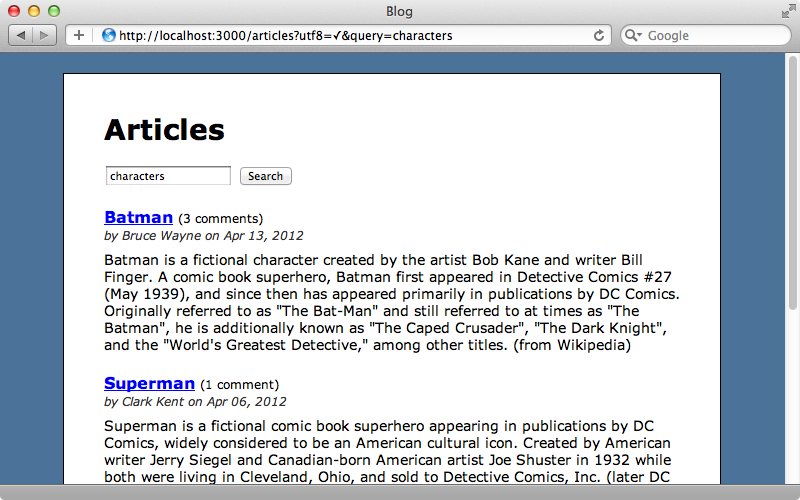
Searching Related Attributes
One useful feature of PgSearch is that it makes it easy to search through related attributes. For example in our application an Article belongs to an Author and has many Comments. We can use PgSearch’s associated_against option to include these and we’ll include the author’s name and the comments’ name and content fields.
pg_search_scope :search, against: [:name, :content], using: {tsearch: {dictionary: "english"}}, associated_against: {author: :name, comments: [:name, :content]}
Now a search for “Clark” will return all the articles written by Clark Kent.
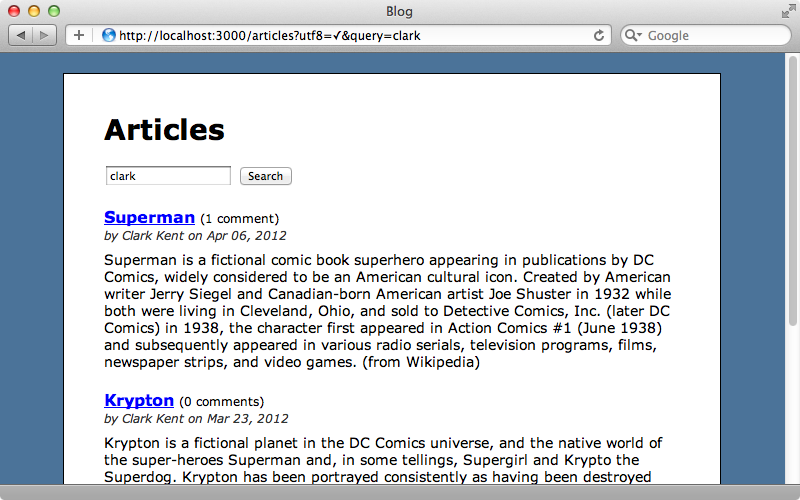
Another of PgSearch’s useful features is the ability to ignore accents.
pg_search_scope :search, against: [:name, :content], using: {tsearch: {dictionary: "english"}}, associated_against: {author: :name, comments: [:name, :content]}, ignoring: :accents
This might not work out of the box and if we reload the page now we’ll get an exception complaining about an undefined function called unaccent in the SQL. To fix this we’ll need to add an extension to our Postgres database. We can do this inside a migration so we’ll create one to do that.
$ rails g migration add_unaccent_extension
This migration will just execute a SQL statement.
class AddUnaccentExtension < ActiveRecord::Migration def up execute "create extension unaccent" end def down execute "drop extension unaccent" end end
We can now run the migration by running rake db:migrate and when we reload the page now the error will be gone. We can search for “süperman” (with an umlaut) now and this will find the articles containing “superman”.
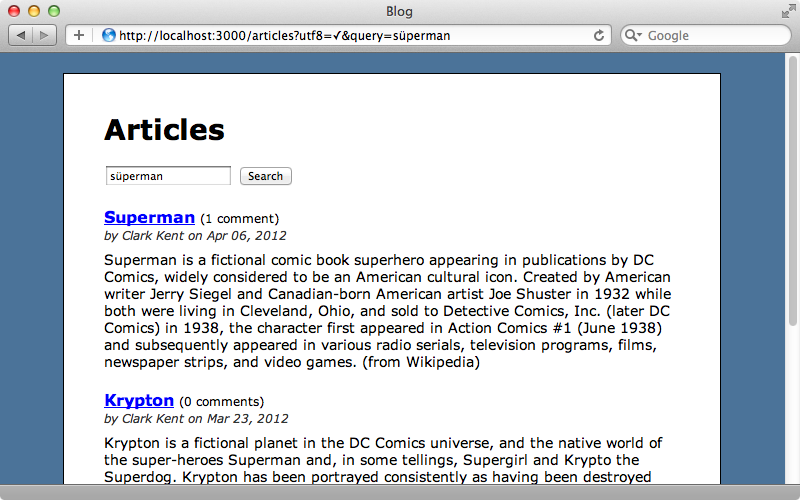
PgSearch provides many other options such as the ability to add weights to certain attributes in the relevance ranking and there’s more information about this in the documentation.
Speeding Up Searches
Let’s shift gears now and focus on performance. We can see from the log that the search query only takes a couple of milliseconds to run but as we only have a few records in the database this isn’t really a surprise. To see how searching performs under more realistic conditions we’ll need to add more records. The seeds.rb file generates the initial records for our application and we’ll alter this file so it creates each record 1,000 times.
bruce = Author.create! name: "Bruce Wayne" clark = Author.create! name: "Clark Kent" 1000.times do superman = Article.create! name: "Superman", author: clark, published_at: 3.weeks.ago, content: <<-ARTICLE Superman is a fictional comic book superhero appearing in publications by DC Comics, widely considered to be an American cultural icon. Created by American writer Jerry Siegel and Canadian-born American artist Joe Shuster in 1932 while both were living in Cleveland, Ohio, and sold to Detective Comics, Inc. (later DC Comics) in 1938, the character first appeared in Action Comics #1 (June 1938) and subsequently appeared in various radio serials, television programs, films, newspaper strips, and video games. (from Wikipedia) ARTICLE # Some articles and comments omitted. Comment.create! name: "Lois Lane", article: superman, content: <<-COMMENT I want to meet Superman again, does anyone know where I can find him? COMMENT end
We could use a Rake task to do this but this will work as a quick and dirty way to create the records. We can run the file by running rake db:seed. We’ll also go back to our Article model and change back to the more manual search so that we have a simpler query that we can focus on optimizing.
def self.text_search(query) if query.present? # search(query) rank = <<-RANK ts_rank(to_tsvector(name), plainto_tsquery(#{sanitize(query)})) + ts_rank(to_tsvector(content), plainto_tsquery(#{sanitize(query)})) RANK where("name @@ :q or content @@ :q", q: "%#{query}%").order("#{rank} DESC") else scoped end end
When we make a search now it takes a noticeable time to run. If we look at the log we’ll see that the search took almost a second to complete, long enough for Rails’ auto-explain to kick in and run an EXPLAIN on the query. The main problem is missing indexes and adding one will make a big difference to the speed. We should add an index to whatever’s on the left side of the @@ operators, in this case the name and content fields. Also it’s not good to rely on the auto-typecasting so we’ll expand out the query.
def self.text_search(query) if query.present? # search(query) rank = <<-RANK ts_rank(to_tsvector(name), plainto_tsquery(#{sanitize(query)})) + ts_rank(to_tsvector(content), plainto_tsquery(#{sanitize(query)})) RANK where("to_tsvector('english', name) @@ :q or to_tsvector('english', content) @@ :q", q: query).order("#{rank} DESC") else scoped end end
This is the same query that we had before but now we have something more concrete that we can add an index to. We’ll generate a migration to add the indexes.
$ rails g migration add_search_index_to_articles
The migration will create the two new indexes.
class AddSearchIndexToArticles < ActiveRecord::Migration def up execute "create index articles_name on articles using gin(to_tsvector('english', name))" execute "create index articles_content on articles using gin(to_tsvector('english', content))" end def down execute "drop index articles_name" execute "drop index articles_content" end end
We create two indexes here, one for the name column and one for content and we use the to_tsvector call like we do in the query to generate the index. Note, though, that we pass this in to a gin method which is a way to efficiently create an index for full-text searching. Postgres offers another indexing function called GiST which is also worth considering. There are more details about these in the documentation but as a rule GIN works best for web applications.
After we’ve migrated our database to add the indexes we can try running another search. This time it runs more quickly and if we look at the logs we’ll see that database query takes about half the time it did before. This is good but it’s not quite the speedup we were hoping for. The primary cause of the remaining slowness is the call to ts_rank as this doesn’t take advantage of the index. If we sort the results by name rather than rank the searches become blazing fast, the log now showing the results running in a few milliseconds. As a compromize we could omit the content field from the relevance ranking. This way there will be some relevance but not as much and the query still runs quickly.
Problems With schema.rb
We’ll finish off this episode by talking about the schema.rb file. This is supposed to be a representation of the full database schema in Ruby but it’s now incomplete. This is because we’ve added some migrations that run SQL code and this is quite common when a Rails application uses Postgres as its database server. If we try to load in the schema file, e.g. when we set up our test database, it will be incomplete. To fix this we can uncomment the following line in our application config file.
# Use SQL instead of Active Record's schema dumper when creating the database. # This is necessary if your schema can't be completely dumped by the schema dumper, # like if you have constraints or database-specific column types config.active_record.schema_format = :sql
If we run rake db:migrate now the schema file will be generated in SQL. A new structure.sql file will be created and this will include everything we need to generate the database. We can now remove the db/schema.rb file. If we ever need to load or dump the schema data now we should use the db:structure:load and db:structure:dump Rake tasks and not the schema tasks.
