
#337 Capistrano Recipes pro
- Download:
- source code
- mp4
- m4v
- webm
- ogv
In last week’s Pro episode we showed how to deploy a Rails application to a VPS. Doing this required us to run a large number of commands to install and configure the software we needed to set up the server to be able run our application. There are a number of tools available that can help to automate all this such as Chef, which will be covered in a future episode, but in this episode we’ll show you how to move much of the server setup into Capistrano recipes so that we can simplify the deployment. To do this we’ll use the application we deployed in episode 335. In that episode we set up a Rails application and deployed it with a Capistrano deployment recipe. There are several things about the deployment that weren’t handled perfectly so in this episode we’ll focus on improving the recipe. First we’ll take a look at it and describe how it works. If you’re unfamiliar with Capistrano take a look at episode 133 first which covers the basics. Here’s the first part of the file.
require "bundler/capistrano" server "178.xxx.xxx.xxx", :web, :app, :db, primary: true set :application, "blog" set :user, "deployer" set :deploy_to, "/home/#{user}/apps/#{application}" set :deploy_via, :remote_cache set :use_sudo, false set :scm, "git" set :repository, "git@github.com:eifion/#{application}.git" set :branch, "master" default_run_options[:pty] = true ssh_options[:forward_agent] = true after "deploy", "deploy:cleanup" # keep only the last 5 releases
The first line here requires bundler/capistrano. This sets up Bundler when we deploy so it’s important to have this line if our application uses Bundler. Next we tell Capistrano the address of the server that the application is to be deployed to and give it all the roles as we’re deploying everything to the same server. We then set the user that the application will be deployed as and the app’s name.
Next we set the deploy path. The line after this is interesting: this keeps a copy of the Git repository on the server cache so that it can be updated without having to clone the repository each time we deploy the application. In the next line the :use_sudo option is set to false; this tells Capistrano not to use sudo when running its internal commands and this can be necessary to avoid permission issues.
In the next block of commands we tell Capistrano that we’re using Git for source control and tell it where the repository is and what branch to use. The first line in the block after that sets the :pty option so that the password prompt works while the second authorizes the server to access the Git repository so that we don’t have to add a deploy key to Github. Finally we tell Capistrano to run the deploy:cleanup task after deploying so that the old releases are removed. All of this is good and we’ll keep this part of the file as it is. What we want to focus on improving are the tasks in the rest of the file.
namespace :deploy do %w[start stop restart].each do |command| desc "#{command} unicorn server" task command, roles: :app, except: {no_release: true} do run "/etc/init.d/unicorn_#{application} #{command}" end end task :setup_config, roles: :app do sudo "ln -nfs #{current_path}/config/nginx.conf /etc/nginx/sites-enabled/#{application}" sudo "ln -nfs #{current_path}/config/unicorn_init.sh /etc/init.d/unicorn_#{application}" run "mkdir -p #{shared_path}/config" put File.read("config/database.example.yml"), "#{shared_path}/config/database.yml" puts "Now edit the config files in #{shared_path}." end after "deploy:setup", "deploy:setup_config" task :symlink_config, roles: :app do run "ln -nfs #{shared_path}/config/database.yml #{release_path}/config/database.yml" end after "deploy:finalize_update", "deploy:symlink_config" desc "Make sure local git is in sync with remote." task :check_revision, roles: :web do unless `git rev-parse HEAD` == `git rev-parse origin/master` puts "WARNING: HEAD is not the same as origin/master" puts "Run `git push` to sync changes." exit end end before "deploy", "deploy:check_revision" end
At the top of this section of the file we override the start, stop and restart deploy tasks and pass the command to the Unicorn script on the server so that Unicorn will be restarted. This Unicorn init script is defined in our application in a unicorn_init.sh file. This file is symlinked to its proper location under /etc/init.d in the setup_config task and we do something similar with the Nginx configuration file in the line above that. This task also copies over the example database YML file to the server. This all happens when we run the deploy:setup task. After each deployment the symlink_config task is run which symlinks the database.yml file to the correct directory in the newly-deployed release. Finally we have a task which checks that the Git repository is up to date before attempting to deploy.
Improving Recipes With Templates
The problem we have with this setup is that the deployment tasks are jumbled together and rather unorganized. If the deployment process grows in complexity this file will only become a bigger mess. Another issue is that configuration files which are only used in deployment are mixed in with the application’s other configuration files.
There’s also a lot of duplication between the configuration files. For example the nginx.conf file contains the path that the application is deployed to. This is also mentioned in the Captistrano deployment file, the Unicorn configuration file and the Unicorn init script. All these files define the same path and it would be nice to remove this duplication. It’s time to clean up our deployment recipe. Instead of defining all the tasks inside the deploy.rb file we’ll make smaller recipe files and define the tasks there. We’ll put these recipe files in a new recipes directory under the config directory and in here we’ll create a new file that relates to each part of the deployment. We’ll start with Nginx; in our new nginx.rb file we’ll define a namespace to set these tasks apart and we’ll create a setup task which will be run after the deploy:setup task.
namespace :nginx do task :setup do end after "deploy:setup", "nginx:setup" end
Any code for setting up Nginx belongs nicely here. We could put the line of code from our deploy.rb file that symlinks the nginx.conf file into this task but instead we’ll do something a little fancier as nginx.conf has some duplication which we can remove by dynamically generating this file based on the data in the Capistrano deploy file. Instead of symlinking nginx.conf in this file we’ll generate this file using erb. We’ll need an erb template to read from and so we’ll create a new templates directory under recipes to put it in. We can move our nginx.conf file into this directory and rename it to nginx_unicorn.erb. The unicorn part reflects the fact that this file is specifically for Nginx and Unicorn together. As this file will be interpreted in the context of Capistrano we have access to all its settings so instead of hard-coding the application’s name in here we can use the application variable. Similarly we can replace the application’s path with current_path.
upstream unicorn {
server unix:/tmp/unicorn.<%= application %>.sock fail_timeout=0;
}
server {
listen 80 default deferred;
# server_name example.com;
root <%= current_path %>/public;
# Rest of file omitted.Now we just need to interpret this file through erb.
namespace :nginx do task :setup do erb = File.read(File.expand_path("../templates/nginx_unicorn.erb"), __FILE__) result = ERB.new(erb).result(binding) put result, "/tmp/nginx_conf" run "#{sudo} mv /tmp/nginx_conf /etc/nginx/sites-enabled/#{application}" end after "deploy:setup", "nginx:setup" end
We get the contents of the template with File.read and we calculate its full path by using expand_path. We then put the contents of this file into a new instance of ERB and call result on it, passing in binding so that we have access to all of the methods here. We can use put to take that result and copy it to a temporary location then use run with #{sudo} to move it to the correct directory. This two-step approach is necessary as we need sudo privileges to write to /etc and put doesn’t run under sudo. Note that we’re using sudo differently from how we used it in episode 335 where we used a sudo command instead of calling run with #{sudo}. This is because the sudo command is now deprecated.
What we’ve done here requires quite a bit of code. This approach of using an erb template is something we’ll be doing in other recipes so we’ll extract this out into a separate method. What we want is a new template method that takes the name of a template and an output path and which processes the template and copies it to that path. We can then use this in our recipes like this:
namespace :nginx do task :setup do template "nginx_unicorn.erb", "/tmp/nginx_conf" run "#{sudo} mv /tmp/nginx_conf /etc/nginx/sites-enabled/#{application}" end after "deploy:setup", "nginx:setup" end
We’ll create this method in a new base.rb file.
def template(from, to) erb = File.read(File.expand_path("../templates/#{from}"), __FILE__) put ERB.new(erb).result(binding), to end
Installing Nginx Through Capistrano
Once we start creating recipe files like this its easy to find commands that we’d normally have to run manually on the server and move them into a new recipe file. For example towards the end of our deployment we need to remove the Nginx configuration for the default site and restart Nginx.
sudo rm /etc/nginx/sites-enabled/default sudo service nginx restart sudo /usr/sbin/update-rc.d -f unicorn_blog defaults
This is something that we can easily move into our new setup task.
namespace :nginx do task :setup do template "nginx_unicorn.erb", "/tmp/nginx_conf" run "#{sudo} mv /tmp/nginx_conf /etc/nginx/sites-enabled/#{application}" run "#{sudo} rm -f /etc/nginx/sites-enabled/default" run "#{sudo} service nginx restart" end after "deploy:setup", "nginx:setup" end
Restarting Nginx might work better as a separate task, however, so that we can call it separately if we need to. We’ll create a task for handling starting, stopping and restarting Nginx and move this code there. We can then call our new restart task from setup.
namespace :nginx do task :setup do template "nginx_unicorn.erb", "/tmp/nginx_conf" run "#{sudo} mv /tmp/nginx_conf /etc/nginx/sites-enabled/#{application}" run "#{sudo} rm -f /etc/nginx/sites-enabled/default" restart end after "deploy:setup", "nginx:setup" %w[start stop restart].each do |command| task command do run "#{sudo} service nginx #{command}" end end end
We could take this a step further and handle the installation of Nginx through Capistrano as well. We can create an install task to do this.
namespace :nginx do task :install do run "#{sudo} add-apt-repository ppa:nginx/stable" run "#{sudo} apt-get -y update" run "#{sudo} apt-get -y install nginx" end after "deploy:install", "nginx:install" # Other task omitted. end
Note that this task will run after a deploy:install task so that we have one command for installing everything we need. All the installation tasks we create will be run through a callback in the same way. We’ll define deploy:install in the base.rb file and it will install and update everything needed to install the rest of the software.
namespace :deploy do task :install do run "#{sudo} apt-get -y update" run "#{sudo} apt-get -y install python-software-properties" end end
Running deploy:install will now install everything else that we have recipes for. Our Nginx recipe is now pretty much complete but we haven’t specified the roles that the tasks should run under. If our application uses multiple servers we only want these tasks to be run for the web server role so we’ll restrict each task to the web role. Now is a good time to add some documentation to the tasks, too.
namespace :nginx do desc "Install latest stable release of nginx." task :install, roles: :web do run "#{sudo} add-apt-repository ppa:nginx/stable" run "#{sudo} apt-get -y update" run "#{sudo} apt-get -y install nginx" end after "deploy:install", "nginx:install" desc "Setup nginx configuration for this application." task :setup, roles: :web do template "nginx_unicorn.erb", "/tmp/nginx_conf" run "#{sudo} mv /tmp/nginx_conf /etc/nginx/sites-enabled/#{application}" run "#{sudo} rm -f /etc/nginx/sites-enabled/default" restart end after "deploy:setup", "nginx:setup" %w[start stop restart].each do |command| desc "#{command} nginx." task command, roles: :web do run "#{sudo} service nginx #{command}" end end end
We still can’t run any of these tasks through Capistrano as these files are not loaded. To fix this we add theses files to deploy.rb so that they’re loaded.
require "bundler/capistrano" load "config/recipes/base" load "config/recipes/nginx" server "178.xxx.xxx.xxx", :web, :app, :db, primary: true set :application, "blog" set :user, "deployer" set :deploy_to, "/home/#{user}/apps/#{application}" set :deploy_via, :remote_cache set :use_sudo, false set :scm, "git" set :repository, "git@github.com:eifion/#{application}.git" set :branch, "master" default_run_options[:pty] = true ssh_options[:forward_agent] = true after "deploy", "deploy:cleanup" # keep only the last 5 releases
We can add any of our recipes to this file and listing them individually allows us to control the load order so that we can resolve any dependency issues. If we run cap -T now we’ll see our Nginx tasks listed.
$ cap -T | grep nginx cap nginx:install # Install latest stable release of nginx. cap nginx:restart # restart nginx. cap nginx:setup # Setup nginx configuration for this application. cap nginx:start # start nginx. cap nginx:stop # stop nginx.
Creating The Other Recipes
With this pattern established we can now make recipes for other parts of the server installation process, too.
require "bundler/capistrano" load "config/recipes/base" load "config/recipes/nginx" load "config/recipes/unicorn" load "config/recipes/postgresql" load "config/recipes/nodejs" load "config/recipes/rbenv" load "config/recipes/check" # Rest of file omitted.
Lets take a look at some of these new recipes starting with the one for Unicorn.
set_default(:unicorn_user) { user } set_default(:unicorn_pid) { "#{current_path}/tmp/pids/unicorn.pid" } set_default(:unicorn_config) { "#{shared_path}/config/unicorn.rb" } set_default(:unicorn_log) { "#{shared_path}/log/unicorn.log" } set_default(:unicorn_workers, 2) namespace :unicorn do desc "Setup Unicorn initializer and app configuration" task :setup, roles: :app do run "mkdir -p #{shared_path}/config" template "unicorn.rb.erb", unicorn_config template "unicorn_init.erb", "/tmp/unicorn_init" run "chmod +x /tmp/unicorn_init" run "#{sudo} mv /tmp/unicorn_init /etc/init.d/unicorn_#{application}" run "#{sudo} update-rc.d -f unicorn_#{application} defaults" end after "deploy:setup", "unicorn:setup" %w[start stop restart].each do |command| desc "#{command} unicorn" task command, roles: :app do run "service unicorn_#{application} #{command}" end after "deploy:#{command}", "unicorn:#{command}" end end
One thing that’s unique about this recipe is that we set some variables at the top using a method called set_default. This allows us to configure how Unicorn is set up and to override variables. For example if we want to increase the number of Unicorn workers we can change the unicorn_workers value in this recipe. The set_default method is defined in base.rb. This is a simple method that sets a value unless it exists already.
def set_default(name, *args, &block) set(name, *args, &block) unless exists?(name) end
Capistrano provides a method called _cset which does much the same thing but by defining our own method we’re safe if the internal _cset method is changed in the future. We also use this method in the Postgres recipe to set values for the host, username, password and database.
set_default(:postgresql_host, "localhost") set_default(:postgresql_user) { application } set_default(:postgresql_password) { Capistrano::CLI.password_prompt "PostgreSQL Password: " } set_default(:postgresql_database) { "#{application}_production" } # Rest of file omitted.
The postgressql_password variable is interesting. Instead of setting a value here we use Capistrano::CLI.password_prompt to prompt for a password that the user can enter. This is just another variable, however, so we could override this in deploy.rb if we want to provide the password in another way.
Trying Our Recipes Out
Now the moment of truth. Let’s try out our new recipes on a new, blank server. First we’ll log in to our Linode server and rebuild it so that we have a clean installation to work with. Once it has rebooted we’ll SSH into it as the root user. All need need to do now is create the deployer user and add them to the admin group.
$ ssh root@178.xxx.xxx.xxx
The authenticity of host '178.xxx.xxx.xxx (178.xxx.xxx.xxx)' can't be established.
RSA key fingerprint is 3b:db:b8:78:84:9b:b0:61:e6:67:df:31:84:47:42:d9.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '178.xxx.xxx.xxx' (RSA) to the list of known hosts.
root@178.xxx.xxx.xxx's password:
Linux li349-144 3.0.18-linode43 #1 SMP Mon Jan 30 11:44:09 EST 2012 i686 GNU/Linux
Ubuntu 10.04.2 LTS
Welcome to Ubuntu!
* Documentation: https://help.ubuntu.com/
0 packages can be updated.
0 updates are security updates.
Ubuntu 10.04.2 LTS
Welcome to Ubuntu!
* Documentation: https://help.ubuntu.com/
root@li349-144:~# adduser deployer --ingroup admin
Adding user `deployer' ...
Adding new user `deployer' (1000) with group `admin' ...
Creating home directory `/home/deployer' ...
Copying files from `/etc/skel' ...
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for deployer
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] YWe can now exit from the server and deploy our application. First we’ll need to run cap deploy:install to update the server and install the software it needs.
$ cap deploy:install
This will take a good few minutes to install everything but we can just let it run. When it finishes we can run cap deploy:setup to setup the configuration for our application.
$ cap deploy:setup
We’ll need to type the password for deployer again and further down the recipe we’ll need to enter a password for Postgresql to use. The recipe will then create a database with that password. There’s just one more command we need to run to install our application.
$ cap deploy:cold
Once this command completes we can try browsing our application in the browser.
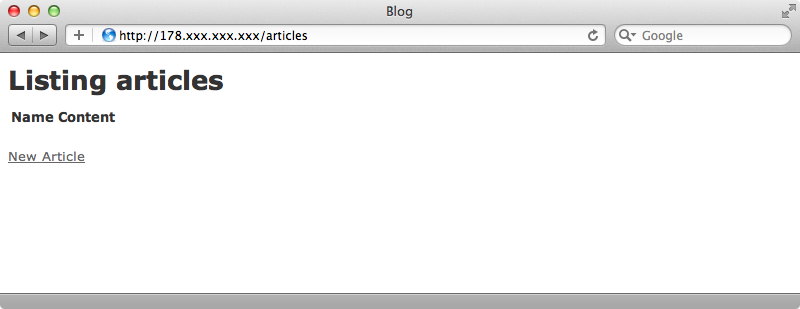
It works! Our application can now be deployed to a new server by running just three commands. That’s it for this episode. Capistrano recipes are quite powerful and can be used to set up a server from scratch as we’ve shown here. If we make our recipes generic enough then we should be able to copy them over to another Rails application with a similar deployment stack and deploy it in the same way.
