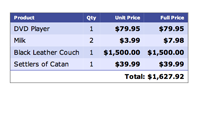
#220 PDFKit
Generating PDFs in plain Ruby can be a lot of work. Instead, consider generating PDFs from HTML using PDFKit.
- Download:
- source code
- mp4
- m4v
- webm
- ogv
Resources
- Episode 153: PDFs with Prawn
- Rethinking PDF Creation in Ruby
- PDFKit
- wicked_pdf
- Full episode source code
Gemfile
gem 'pdfkit'
bash
bundle install rake middleware
config/application.rb
config.middleware.use "PDFKit::Middleware", :print_media_type => true
layouts/application.html.erb
<%= stylesheet_link_tag 'application', :media => "all" %>
orders/show.html.erb
<p id="pdf_link"><%= link_to "Download Invoice (PDF)", order_path(@order, :format => "pdf") %></p>
application.css
@media print { body { background-color: #FFF; } #container { width: auto; margin: 0; padding: 0; border: none; } #line_items { page-break-before: always; } #pdf_link { display: none; } }
