#22 Eager Loading
要想试图优化你的Rails应用,首先应当把目光投向数据库访问操作。减少对数据库的访问次数能对应用的运行效率产生巨大的提升作用。下面来介绍一种叫做贪婪读取的技术
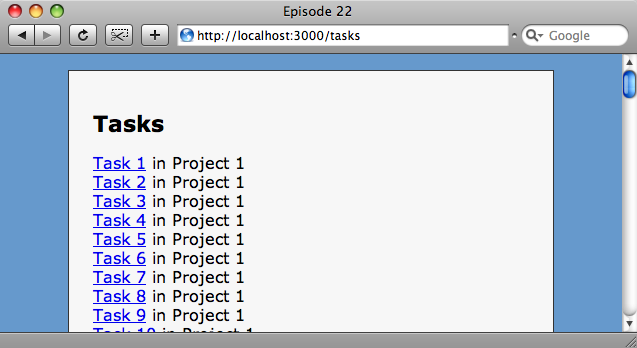
这个示例应用包含两个模型分别是任务(Task)和项目(Project)
图中的页面列出了一系列任务以及每个任务所属于的项目。在TaskController代码里便利所有的任务,在视图中通过循环将他们一一列出。
<h1>Tasks</h1> <ul> <% @tasks.each do |task| %> <li><%= link_to task.name, task %> in <%= task.project.name %></li> <% end %> </ul>
代码中获取任务的名称,然后再通过级联访问到关联的项目并得到项目名称。这里就有问题了,可以通过查看日志了解到,每一次尝试获取任务所属于的项目的名称时,都会发起一次SQL查询。
Project Load (0.2ms) SELECT * FROM "projects" WHERE ("projects"."id" = 60)
CACHE (0.0ms) SELECT * FROM "projects" WHERE ("projects"."id" = 60)
CACHE (0.0ms) SELECT * FROM "projects" WHERE ("projects"."id" = 60)
CACHE (0.0ms) SELECT * FROM "projects" WHERE ("projects"."id" = 60)
CACHE (0.0ms) SELECT * FROM "projects" WHERE ("projects"."id" = 60)循环操作造成了大量的数据库访问。
能够看出,每当尝试获取项目名称时,都会执行相同的SQL调用。目前的Rails版本已经没有这个问题了,在Rails 2.0版本以后加入了缓存机制以便减少访问次数,但在以前的版本里没有这个功能。
缓存机制是能够发挥作用的,使用贪婪读取功能能够进一步降低访问次数。可以通过修改code>TasksController将其开启。
class TasksController < ApplicationController
def index
@tasks = Task.find(:all, :include => :project)
end
end通过增加:include => :project参数告诉Rails在读取任务对象的同时将关联着的项目也一并读回来。这里使用:project单数而不是复数,因为任务belongs_to项目,即只和一个项目对应。修改之后再刷新页面后察看日志,SQL调用大大降低,效率得到了改善。
在将更多的级连查寻上使用贪婪加载
除了有一个Project的引用,Task类还关联多个Comment对象。
class Task < ActiveRecord::Base belongs_to :project has_many :comments end
将两个字段都进行贪婪加载需要把他们写在一个列表中作为参数。(请注意,:comments使用的是复数,因为关联关系是has_many。)
class TasksController < ApplicationController def index @tasks = Task.find(:all, :include => [:project, :comments]) end end
还有可能面对更加复杂一些的级连关系,Comment还引用着User。希望能够在加载Task的时候同时也把发表Comment的User一并加载上来。
class Comment < ActiveRecord::Base belongs_to :task belongs_to :user end
下一层的引用关系通过hash参数表示。
@tasks = Task.find(:all, :include => [:project, {:comments => :user }])
使用贪婪加载可以通过减少数据库访问次数提高应用的性能。更多信息可以到Rails的API文档中去了解。http://api.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html
