#190 Screen Scraping with Nokogiri
- Download:
- source code
- mp4
- m4v
- webm
- ogv
在173集中[观看,阅读],使用过ScrAPI库来做页面抓取. 页面抓取是个热门话题,有很多gems和插件就是专门方便处理这个的. 本集将使用不同的工具,再次来提起这个话题. 看完这集后,你可以回去阅读并比较之前提到的,看哪个更适合你.
上次我们有一个没有价格的商品列表应用,然后试图从其他网站, 比如从沃尔玛walmart.com上找到这些商品的价格.
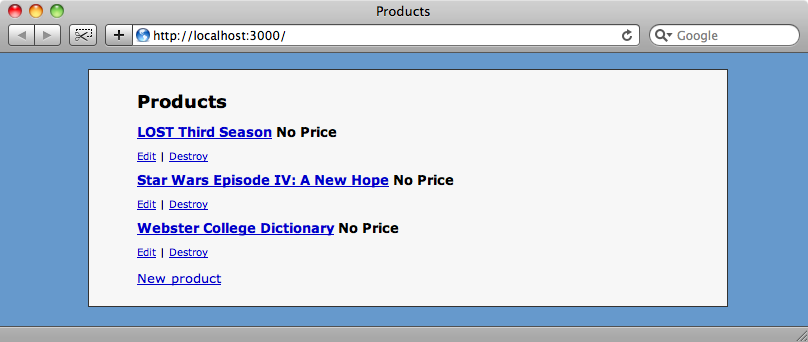
我们在walmart.com主页搜索一个商品, 会转向匹配到该商品并带有价格的列表页面. 我们可以使用这个页面来获取我们网站上缺失的价格.
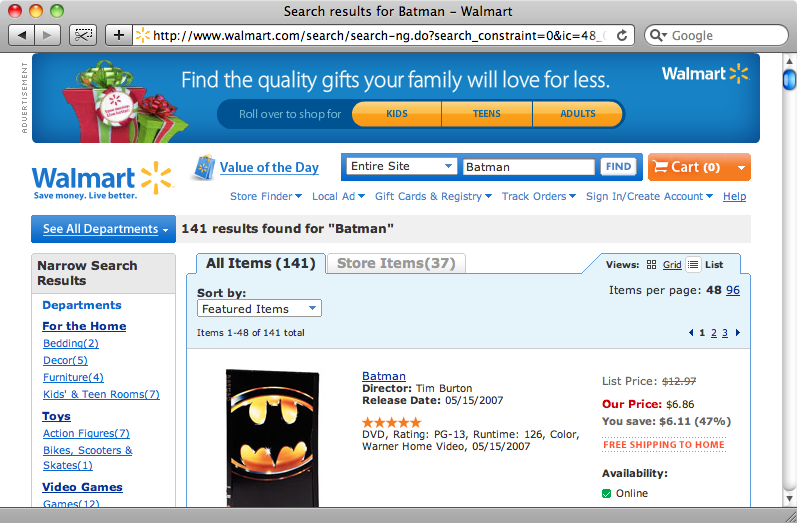
"Batman"的搜索结果页面
前面提到过,抓取目标网站的页面数据时,要确保有足够的权限. 有些网站明确禁止页面抓取数据,因此在开始前,你应该确认目标网站的页面抓取工作是被允许的. 如果网站提供RSS订阅或是API获取数据,对于信息的获取,这将是一个更好的办法. 因为这两个方式在沃尔玛网站上都行不通,所以我们还是需要进行页面抓取.
安装Nokogiri
上次我们使用ScrAPI库来解决数据抓取工作,这次我们将使用Nokogiri. 它可以解析HTML和XML文档并从中提取内容. Nokogiri是一个区别于ScrAPI并且速度很快的接口,通过它可以更直接地操作HTML文档,而不是一切都依赖于DSL.
如果你用的是Mac,并且是在Snow Leopard上面写Rails应用,那么安装Nokogiri只需直接输入下面命令:
sudo gem install nokogiri
如果你用的是一个较旧的OS X或是其他的操作系统,那么你需要先手动安装libxml2库,并指定它的路径,然后再通过gem安装Nokogiri. 举个例子,你可以用下面的命令先把libxml2安装到 /usr/local下;
sudo gem install nokogiri -- --with-xml2-include=/usr/local/include/libxml2 --with-xml2-lib=/usr/local/lib
关于OS X, Linux, Windows上Nokogiri的详细安装过程,可以参考这篇安装教程.
开始使用Nokogiri
安装好 Nokogiri后,就可以开始使用了. Nokogiri可以使用 Xpath或是CSS选择器来定位页面内容. CSS选择器比较适合从HTML文档中抓取数据.
在Rails应用里使用Nokogiri前,我们先通过一个Ruby脚本来实践一下Nokogiri. 通过使用刚才在walmart.com上"Batman"的搜索结果页的URL,我们先尝试提取页面的标题.
require 'rubygems' require 'nokogiri' require 'open-uri' url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) puts doc.at_css("title").text
除了需要引用 nokogiri 外,还需要引用open-uri来帮助我们获取一个URL的页面内容,然后创建一个Nokogiri HTML文档,就可以把搜索结果页的页面内容传给它,在Nokogiri文档中,我们可以使用at_css作为css选择器来检索title,然后提取<title>元素里面的内容. at_css方法将返回第一个匹配到的title元素, 调用.text可以获得它的文本内容.最后我们可以用puts把内容打印出来.
运行脚本,将可以看到页面的标题内容:
Search results for Batman - Walmart
接下来尝试稍微复杂点的:检索搜索结果页上每一个商品的名称和价格。首先需要做的是找到它们的CSS选择器,然后去匹配相应的页面部分。上一集的页面抓取我们使用了一个Firefox插件来解决这个问题,这一次我们将使用一个叫SelectorGadget的书签. 要使用它,只需要从它的官网上将链接拖到浏览器书签栏,这是一个在Firefox和Safari上都能工作的书签SelectorGadget.
现在,回到之前的搜索页面,我们要找出匹配每个商品标题的css选择器.如果我们点击页面上的第一个标题,对应的css selector将会被显示在页面上.滚动页面,点击其他的商品,其他的商品匹配到的css selector也会被显示. 用 .prodLink , 我们可以匹配到页面上的每一个标题,这正是我们需要的.
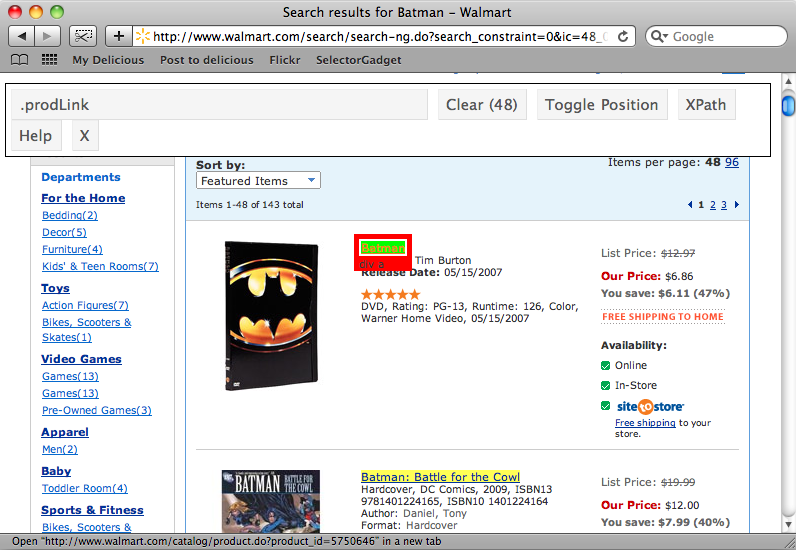
现在我们还需要匹配每一个商品的价格的css选择器。这里会稍微有点复杂。如果我们选择了页面顶部的一个价格,我们会发现,不是所有的价格都被选中.然后可以点击一个没有被选中的价格,让所有价格都被选中,但是却又发现不需要的一些元素也被选中了,在这种情况下,点击那些不需要的元素让它们处于不被选中状态,最终我们可以只让价格被选中. 然后复制SelectorGadget提供的css选择器: .PriceXLBold, .PriceCompare . BodyS
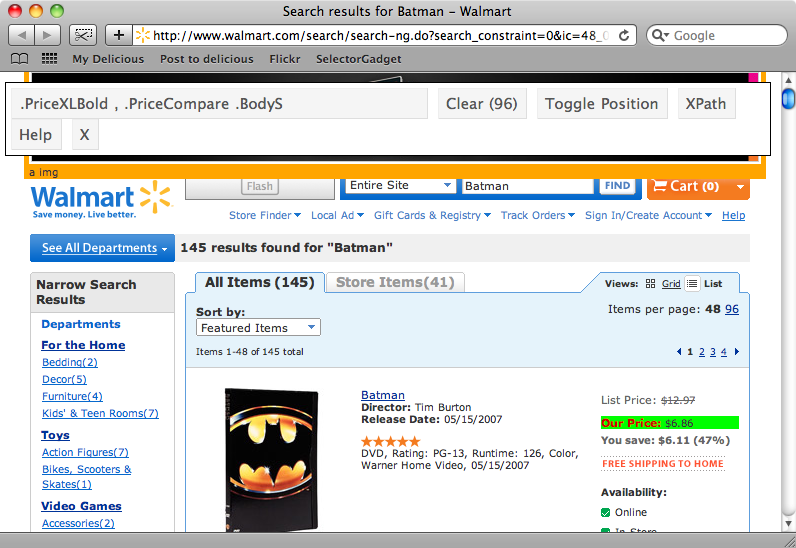
最后还需要的css选择器是匹配列表中的每一个商品.点击第一个,可以得到只匹配第一个的css选择器,当点击第二个商品后,可以得到匹配页面所有商品的css选择器 .item
现在我们已经获得了页面上需要使用的所有css选择器,修改刚才的脚本:
require 'rubygems' require 'nokogiri' require 'open-uri' url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) doc.css(".item").each do |item| puts item.at_css(".prodLink").text end
我们现在做的是使用.item选择器来循环每一个商品,然后抓取每一个带有.prodLink的商品标题。如果再次运行脚本,就可以看到每一个商品的标题列表.
$ ruby test.rb Batman Batman: No Man's Land Batman: No Man's Land - Vol 03 Batman: No Man's Land - Vol 02 Fisher-Price Batman Lights and Sounds Trike Batman: Arkham Asylum (PS3) LEGO Batman (DS) LEGO Batman (Wii) DC Universe Batman / Superman / Catwoman / Lex Luthor / Two-Face Figures Batman Begins (Blu-ray) (Widescreen) LEGO Batman (Xbox 360)
当然,我们还需要每一个商品的价格,再次修改脚本为:
require 'rubygems' require 'nokogiri' require 'open-uri' url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) doc.css(".item").each do |item| text = item.at_css(".prodLink").text price = item.at_css(".PriceXLBold, .PriceCompare .BodyS").text[/\$[0-9\.]+/] puts "#{text} - #{price}" end
通过css选择器我们获得了商品的标题和价格。在价格里面会包含一些文本,如 "Our price:$6.99", 所以我们需要用正则表达式去匹配美元符号,和它后面的数字。再次运行脚本,就可以获得页面上每一个商品的标题和价格了:
$ ruby test.rb Batman - $6.86 Batman: No Man's Land - $11.50 Batman: No Man's Land - Vol 03 - $11.50 Batman: No Man's Land - Vol 02 - $9.50 Fisher-Price Batman Lights and Sounds Trike - $43.21 Batman: Arkham Asylum (PS3) - $59.82 LEGO Batman (DS) - $19.82 LEGO Batman (Wii) - $19.82 DC Universe Batman / Superman / Catwoman / Lex Luthor / Two-Face Figures - $44.00 Batman Begins (Blu-ray) (Widescreen) - $11.32 LEGO Batman (Xbox 360) - $19.82
那么如何抓取每一个商品的URL呢 ? 我们会发现商品的标题是锚元素,它的href属性包含了商品的URL,因此,我们要做的是抓取href的值,可以在脚本中添加下面一行代码:
item.at_css(".prodLink")[:href]
收集所有代码
现在我们已经可以用Nokogiri从一个网页里抓取数据,并且能在Rails应用里为每一个商品获得价格了。现在要做的是控制一个rake任务,在/lib/tasks 目录下创建一个文件,命名为product_prices.rake 。
rake任务里面的代码跟我们刚才的ruby脚本代码很相似。先给刚才创建的任务写个描述,这个任务通过运行 :environment 来加载Rails环境,找到数据库中没有价格的所有商品,然后去遍历他们.
对于每一个商品,我们需要知道对于的搜索结果页面的URL. 先通过CGI::Escape来为商品的名字转码来确保它可以被安全嵌入URL. 得到URL后,可以通过Nokogiri来打开,并通过CSS选择器来抓取数据,修改正则表达式,不匹配货币字符. 这样在获取价格后,我们就可以更新商品了。
desc "Fetch product prices" task :fetch_prices => :environment do require 'nokogiri' require 'open-uri' Product.find_all_by_price(nil).each do |product| escaped_product_name = CGI.escape(product.name) url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=#{escaped_product_name}&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) price = doc.at_css(".PriceXLBold, .PriceCompare .BodyS").text[/[0-9\.]+/] product.update_attribute(:price, price) end end
现在可以运行rake任务了
rake fetch_prices
如果运行完成没有错误,我们就可以返回到我们维护的商品列表页面,看看发生了什么.
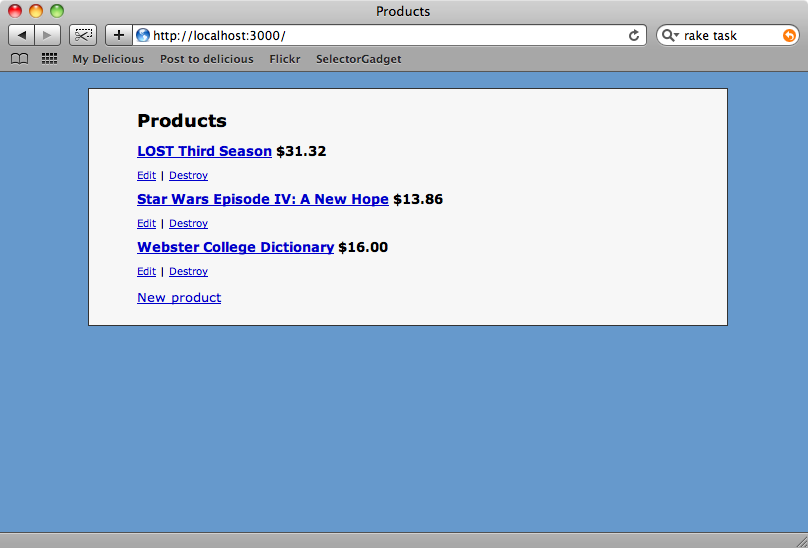
现在所有没有标价格的商品现在都已经标明了walmart.com上对应的价格.
用Nokogiri和SelecorGadget,可以成功地从其他网站抓取数据. 对于页面抓取工作,它们是完美组合。但是如果你需要与网站交互更多的内容,例如在抓取数据前登陆,针对这种情况,我们可以使用Mechanize,下一集我们将介绍它.
