#190 Screen Scraping with Nokogiri
- Download:
- source code
- mp4
- m4v
- webm
- ogv
Nell’episodio 173 [guardalo, leggilo] abbiamo trattato lo screen-scraping con la libreria ScrAPI. Lo screen-scraping è un argomento piuttosto popolare ed esistono svariati plugin e gem che ne rendono semplice la pratica, per cui in questo episodio riprenderemo l’argomento, ma questa volta usando strumenti diversi. Finito di leggere questo episodio, vi invito a rileggere e confrontare l’altro per capire meglio le differenze fra i due approcci e scegliere quello che preferite.
Come abbiamo fatto la volta scorsa, partiamo da una applicazione che ha una lista di prodotti privi di prezzo: vogliamo recuperare i prezzi per tali prodotti da un altro sito, in questo caso walmart.com.
Se cerchiamo un prodotto sul sito di Walmart, veniamo ricondotti ad una pagina che mostra una lista di prodotti corrispondenti al criterio di ricerca immesso, insieme ai loro prezzi. Possiamo utilizzare questa pagina per recuperare i prezzi che ci servono per il nostro sito.
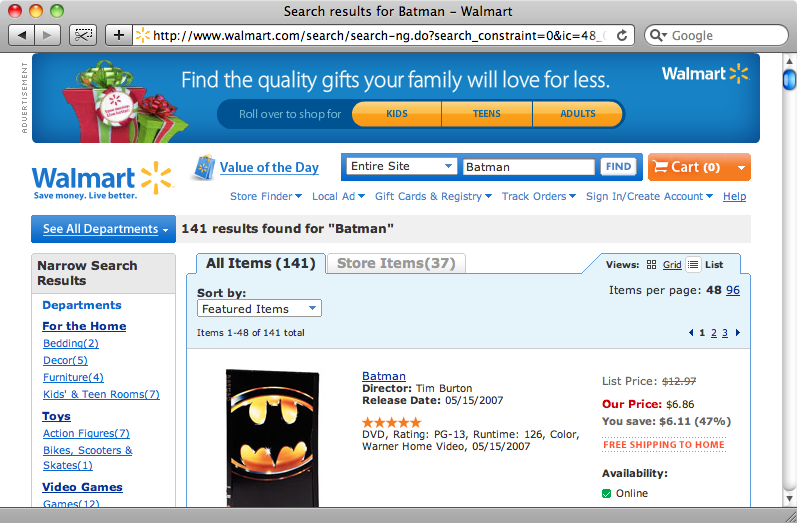
La pagina dei risultati per la ricerca con chiave “Batman”
Come già detto nello scorso episodio sullo screen-scraping, è molto importante assicurarsi di avere i diritti per estrarre i dati dal sito che intendete usare. Alcuni siti proibiscono esplicitamente tecniche simili nei loro confronti, per cui dovete sempre controllare che possiate prendere delle informazioni da un sito prima di farlo. Se il sito fornisce dei feeds RSS oppure una API che già consente il recupero di informazioni da esso, in tal caso è sempre meglio passare da tali canali per ottenere le stesse informazioni. Siccome nessuna di queste soluzioni alternative e preferibili è disponibile sul sito di Walmart, dobbiamo ricorrere allo screen-scraping.
Installare Nokogiri
La volta scorsa abbiamo utilizzato una libreria chiamata ScrAPI per avere un supporto all’estrazione dei dati da altri siti. Questa volta useremo Nokogiri, che è in grado di interpretare documenti HTML e XML ed estrarre dei contenuti da essi. Nokogiri è veloce e l’interfaccia è diversa da quella di ScrAPI, in quanto lavora più a basso livello e direttamente sul documento HTML, anzichè mascherare tutto con un DSL.
Se state scrivendo la vostra applicazione Rails su di un Mac con Snow Leopard, l’installazione di Nokogiri dovrebbe essere rapida quanto lanciare:
sudo gem install nokogiri
Se state invece usando una versione meno recente di OS X o addirittura un sistema operativo differente, allora probabilmente dovrete installare prima di tutto manualmente la libreria libxml2 e poi indicare la sua posizione all’installazione del gem Nokogiri. Per esempio, se avete installato libxml2 sotto /usr/local, allora il comando per l’installazione di Nokogiri dovrebbe essere:
sudo gem install nokogiri -- --with-xml2-include=/usr/local/include/libxml2 --with-xml2-lib=/usr/local/lib
Se avete bisogno di ulteriore supporto all’installazione di Nokogiri, potete dare un’occhiata al tutorial di installazione, dove ci sono istruzioni dettagliate sulla installazione per OS X, Linux e Windows.
Cominciamo a lavorare con Nokogiri
Ora che abbiamo installato Nokogiri, possiamo cominciare ad usarlo. Nokogiri è in grado di sfruttare sia i selettori XPath, sia quelli CSS3, il che lo rende particolarmente adatto ad estrarre dati da pagine HTML.
Cominceremo a provare Nokogiri con uno script Ruby prima di portarlo all’interno della nostra applicazione Rails. Usando l’URL dei risultati della ricerca per la parola chiave “Batman” sul sito di Walmart, proviamo ad estrarre il titolo della pagina.
require 'rubygems' require 'nokogiri' require 'open-uri' url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) puts doc.at_css("title").text
Oltre al gem nokogiri, abbiamo bisogno di open-uri, affinchè ci sia possibile estrarre i contenuti da un URL facilmente. Poi creiamo un nuovo documento HTML Nokogiri, passandogli i contenuti della pagina coi risultati della ricerca. Su questo documento Nokogiri possiamo invocare il metodo at_css, passandogli il selettore CSS "title" per recuperare i contenuti dell’elemento <title>. Il metodo at_css restituirà il primo elemento che fa match col selettore, sul quale potremo invocare il metodo .text per estrarne il contenuto testuale. Infine usiamo puts per stampare a console il testo così recuperato.
Lanciando lo script, dovremmo vedere il contenuto del titolo della pagina:
Search results for Batman - Walmart
Proviamo ora qualcosa di più complicato: recuperare il nome e il prezzo di ogni prodotto dalla pagina dei risultati della ricerca. La prima cosa da decidere è il selettore CSS che faccia match con le parti significative della pagina. Nello scorso episodio sullo screen-scraping abbiamo usato un plugin di Firefox per farlo, ma questa volta utilizzeremo un bookmarklet chiamato SelectorGadget. Per usarlo, è sufficiente trascinare il link dalla home page del sito dentro alla barra dei segnalibri del nostro browser. Essendo un bookmarklet, quindi semplice JavaScript, SelectorGadget funzionerà sia su Safari, sia su Firefox.
Dunque, ritornando alla pagina dei risultati della ricerca, vogliamo trovare il selettore CSS che faccia match con il titolo di ciascun elemento. Se clicchiamo sul primo titolo presente nella pagina, verrà mostrato il selettore che fa match con tale elemento. Se facciamo lo scroll della pagina, ogni altro elemento che fa match col selettore verrà mostrato. Il selettore che abbiamo ora, .prodLink, fa match con ciascun titolo nella pagina, che è esattamente ciò che ci aspettiamo, per cui abbiamo già trovato quello che cercavamo.
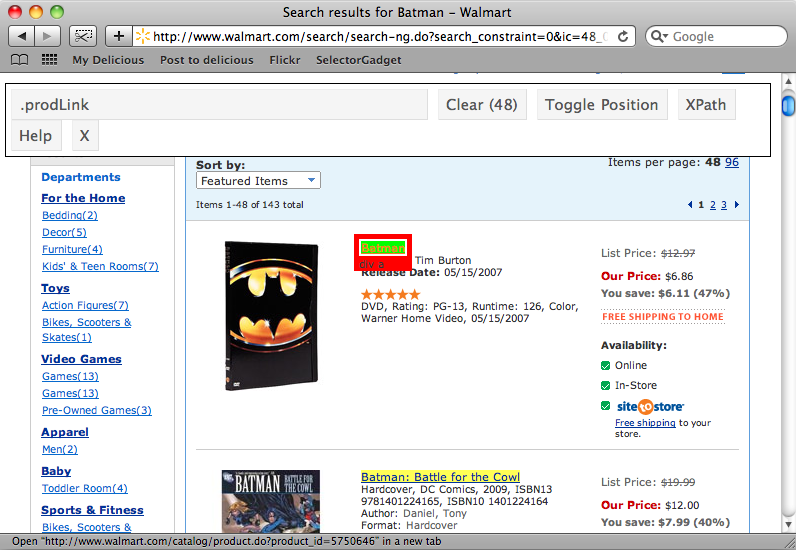
Ora proviamo a cercare un selettore che faccia match con i prezzi di ogni prodotto . Questo è un po’ meno semplice. Se scegliamo uno dei prezzi in cima alla pagina, notiamo come non tutti gli elementi di prezzo verranno selezionati. Scegliendo uno fra i prezzi non selezionati, tutti i prezzi saranno selezionati, ma non solo quelli. Cliccando sugli elementi che non vogliamo per deselezionarli, alla fine ci rimangono proprio solo i prezzi e possiamo quindi copiare il selettore identificato per noi da SelectorGadget, che è .PriceXLBold, .PriceCompare .BodyS.
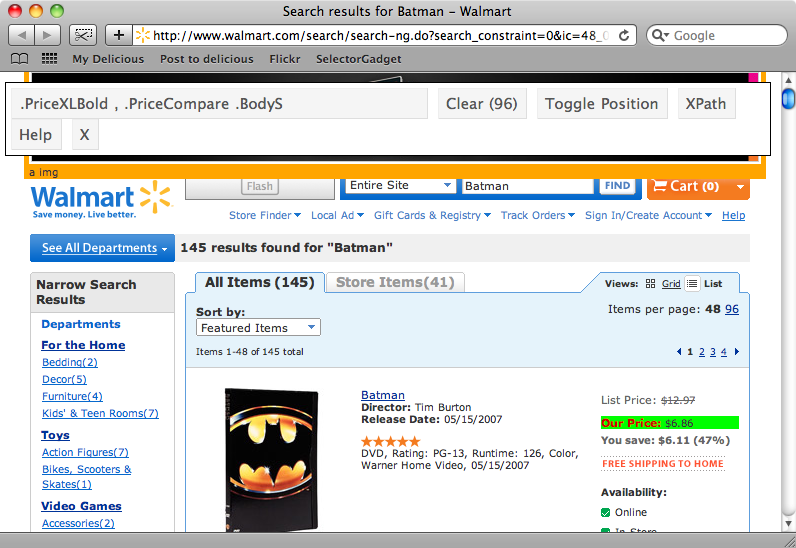
L’ultimo selettore che ci manca è quello che fa match con ciascun elemento nella lista. Se clicchiamo sul primo, ci viene dato un selettore che fa match solo con lui. Una volta che scegliamo il secondo elemento, otteniamo un selettore, .item, che fa match con tutti gli elementi della pagina.
Ora che abbiamo i selettori CSS di cui avevamo bisogno, possiamo usarli nel nostro script per estrarre le informazioni dalla pagina. Modifichiamo dunque lo script in questo modo:
require 'rubygems' require 'nokogiri' require 'open-uri' url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) doc.css(".item").each do |item| puts item.at_css(".prodLink").text end
Quello che stiamo facendo ora è di usare il selettore .item per iterare fra ciascun elemento ed estrarne il titolo col selettore .prodLink. Se lanciamo lo script nuovamente, vedremo elencati i titoli di ogni elemento:
$ ruby test.rb Batman Batman: No Man's Land Batman: No Man's Land - Vol 03 Batman: No Man's Land - Vol 02 Fisher-Price Batman Lights and Sounds Trike Batman: Arkham Asylum (PS3) LEGO Batman (DS) LEGO Batman (Wii) DC Universe Batman / Superman / Catwoman / Lex Luthor / Two-Face Figures Batman Begins (Blu-ray) (Widescreen) LEGO Batman (Xbox 360)
Naturalmente, vogliamo anche il prezzo di ciascun elemento, per cui dobbiamo modificare di nuovo il nostro script:
require 'rubygems' require 'nokogiri' require 'open-uri' url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) doc.css(".item").each do |item| text = item.at_css(".prodLink").text price = item.at_css(".PriceXLBold, .PriceCompare .BodyS").text[/\$[0-9\.]+/] puts "#{text} - #{price}" end
Otteniamo il titolo come prima, poi usiamo il selettore CSS che ci fornisce SelectorGadget per recuperare il prezzo di ciascun prodotto. L’elemento che contiene il prezzo ha anche un po’ di testo al suo interno, per esempio “Our price: $6.99” per cui dobbiamo usare un’espressione regolare che faccia match col simbolo del dollaro e con ciascun numero o punto decimale dopo tale simbolo. Lanciando lo script nuovamente, vedremo il titolo ed il prezzo di ciascun elemento presente in pagina:
$ ruby test.rb Batman - $6.86 Batman: No Man's Land - $11.50 Batman: No Man's Land - Vol 03 - $11.50 Batman: No Man's Land - Vol 02 - $9.50 Fisher-Price Batman Lights and Sounds Trike - $43.21 Batman: Arkham Asylum (PS3) - $59.82 LEGO Batman (DS) - $19.82 LEGO Batman (Wii) - $19.82 DC Universe Batman / Superman / Catwoman / Lex Luthor / Two-Face Figures - $44.00 Batman Begins (Blu-ray) (Widescreen) - $11.32 LEGO Batman (Xbox 360) - $19.82
Come potremmo fare per estrarre anche l’URL di ciascun elemento? Ebbene, l’elemento che contiene il titolo del prodotto è un elemento ancora e il suo attributo href contiene proprio l’URL per quell’elemento, per cui tutto ciò che dobbiamo fare è estrarre il valore di quell’attributo. Lo possiamo fare col seguente codice:
item.at_css(".prodLink")[:href]
Mettiamo tutto assieme
Ora che abbiamo usato Nokogiri per estrarre dati da una pagina web, possiamo usare quanto abbiamo già scritto all’interno della nostra applicazione Rails per ottenere il prezzo di ciascun prodotto. Possiamo farlo mediante un task Rake, per cui nella cartella /lib/tasks dell’applicazione creiamo un nuovo file denominato product_prices.rake per contenere il task.
Il codice nel task Rake sarà simile al codice dello script Ruby che abbiamo scritto poc’anzi. Dopo aver dato una breve descrizione al nostro task, ne definiamo il comportamento. Il task comincia lanciando il task :environment per caricare l’ambiente Rails. Poi trova tutti i prodotti sul database che non hanno un prezzo e itera su di essi.
Per ciascun prodotto, vogliamo ottenere l’URL di ricerca appropriato. Per fare ciò, dobbiamo per prima cosa fare l’escape del nome del prodotto al fine di renderlo sicuro all’interno di un URL; per fare questo, possiamo usare CGI::Escape. Una volta costruito l’URL, possiamo aprirlo con Nokogiri e usare il selettore CSS del nostro script Ruby per estrarre il prezzo. C’è una piccola modifica all’espressione regolare, affinchè non includa più il simbolo della valuta. Una volta ottenuto il prezzo, possiamo aggiornare il prodotto:
desc "Fetch product prices" task :fetch_prices => :environment do require 'nokogiri' require 'open-uri' Product.find_all_by_price(nil).each do |product| escaped_product_name = CGI.escape(product.name) url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=#{escaped_product_name}&Find.x=0&Find.y=0&Find=Find" doc = Nokogiri::HTML(open(url)) price = doc.at_css(".PriceXLBold, .PriceCompare .BodyS").text[/[0-9\.]+/] product.update_attribute(:price, price) end end
Se ora lanciamo il task rake:
rake fetch_prices
esegue senza errori, per cui torniamo alla nostra pagina dei prodotti e vediamo che è successo:
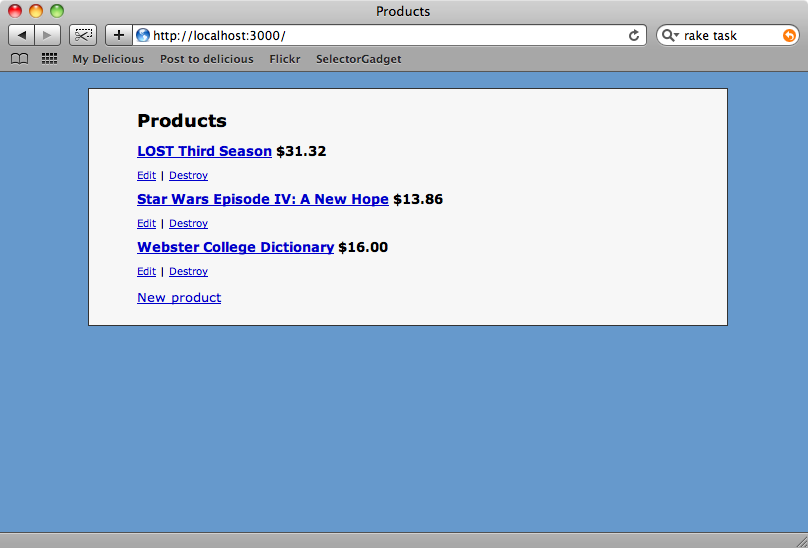
Ora tutti i prodotti hanno il loro prezzo in base a quanto dichiarato dal sito di Walmart.
Con Nokogiri e SelectorGadget abbiamo estratto informazioni con successo da un altro sito web. Insieme rappresentano una potente accoppiata di strumenti utili allo screen-scraping. Ma come potremmo fare se volessimo interagire di più col sito web esterno, per dire, autenticandoci prima di estrarre i dati? Per questo scopo, potremmo usare Mechanize, che verrà trattato nel prossimo episodio.
