#173 Screen Scraping with ScrAPI
- Download:
- source code
- mp4
- m4v
- webm
- ogv
In episode 168 [read, watch] we used Feedzirra to parse and extract RSS feeds. Sometimes, though, the data we want isn’t available via RSS or an API and we have to take the option of last resort: screen scraping. Screen scraping involves downloading a web page’s HTML and parsing it for data and we’ll show you how to do that in this episode.
Price Matching
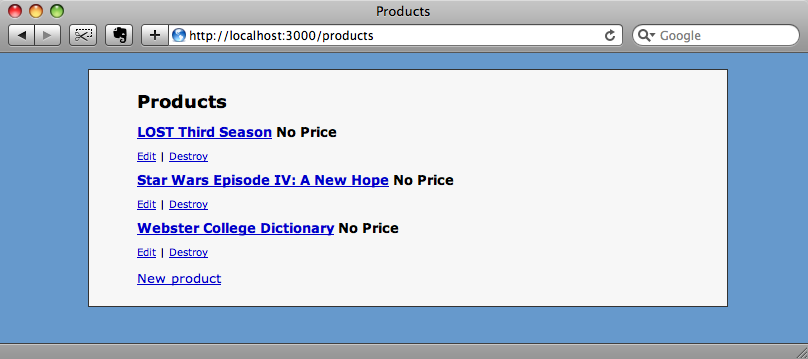
To demonstrate screenscraping we’ll work with a simple shop application. The page below shows a list of products, but none of them have a price. To fix this we’ll fetch the price from another website using screen scraping.
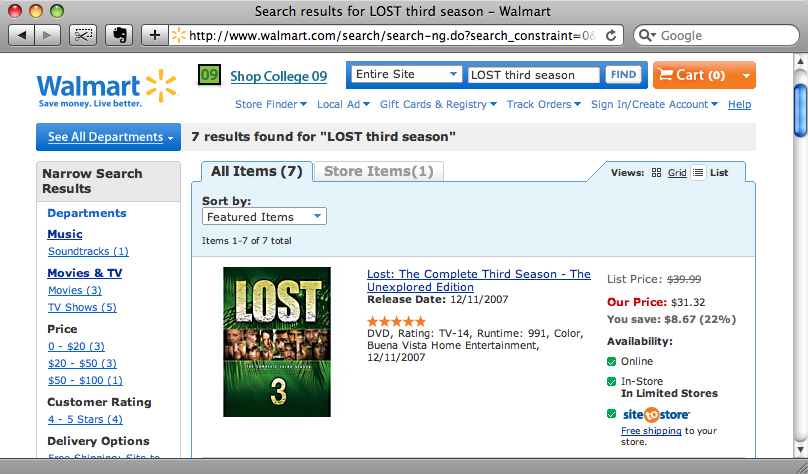
The site we’ll be taking the other prices from is Walmart’s. We’ll search for each product using the search field on the home page then return the price for the first item on the results page.
A quick disclaimer before we continue. Before you dash off and start scraping data from websites willy-nilly you must check that you’re allowed to use the sites in this way. The terms of use may mean that you can’t scrape data; for example IMDB explicitly forbids the scraping of information from its site. If you’re using screen scraping in a production application it is vital to ensure that you’re on safe legal ground.
ScrAPI
There are a variety of Ruby libraries available for screen scraping. Two of the most popular are scRUBYt and scrAPI. One of the main differences between them is that scRUBYt uses XPath for matching while scrAPI uses CSS selectors. I’m more comfortable with CSS selectors so for this episode we’ll use scrAPI.
ScrAPI is available as a gem and is installed in the usual way.
sudo gem install scrapi
ScrAPI relies on the tidy gem so will install that too if you don’t already have it on your machine. Once it’s installed we’ll need to add a reference to it in our application’s /config/environment.rb file.
config.gem "scrapi"
Extracting The Data
Now that our application’s set up we can start trying to scrape the data we need. Before we try getting a price from the results page we’ll start with something a little simpler: extracting the page’s title.
When trying something new it’s often best to start outside a Rails application so that we can quickly experiment and see the results of the code we write. In a new Ruby file we’ll try to scrape the title from the search results page from the Walmart site above. The code to scrape the title looks like this.
require 'rubygems' require 'scrapi' scraper = Scraper.define do process "title", :page_name => :text result :page_name end uri = URI.parse("http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=LOST+third+season&Find.x=17&Find.y=1&Find=Find") puts scraper.scrape(uri)
At the top of the file are the two require statements to load the scrAPI gem. We then define a Scraper and assign it to a variable. We do this by calling Scraper.define and passing it a block. There are a number of methods that we can call in the block; one of the ones that we’ll use often is process.
In the process method we define the content that we’ll scrape from the site. The first argument is the CSS selector that matches the content we want, in our case the title element. We want to assign the result to a variable, we do that by passing a hash as a second argument. The hash’s key is the name of the variable and the value is the part of the matched element we’re interested in which for us is its text.
The other method we use in the scraper’s block is result and this is where we define what’s returned. In the code above we’re just returning the value of page_name.
Now that the scraper is defined we can do the actual scraping. We define the URI we want to parse with URI.parse, passing it the search results page we used earlier, then call scraper.scrape, passing it that URI. Finally in our test code we print out the results of the scrape.
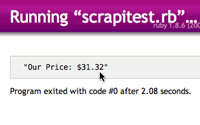
If we run the code above we should see the contents of the title from the page printed out.
$ ruby scrapitest.rb Search results for LOST third season - Walmart
And there it is. Now that we know that scraping works we can try to get the price for the first product on the search results page.
The difficult part of this is getting the right CSS selector to match the element on the page that contains the price. We could try to work it out by looking at the source for the page and determining the elements and classes that would define a selector to match the price element but if we have Firefox then we can make use of an extension called Firequark. Firequark is an extension to Firebug, one of the most popular web development extensions for Firefox. If you have Firebug installed then Firequark will overwrite it so bear that in mind before installing it.
Once it’s installed then we can use it to get our CSS selector. If we right-click on the item’s price in Firefox and select “Inspect Element” from the pop-up menu then Firebug will open and show the source around that element. We can then right-click on that element and we’ll see the extra menu options that Firequark creates. The two we’re interested in are “Copy CSS Selector” and “Copy U CSS Selector”. These differ in that the second one will create a selector that matches only the element we’ve selected while the first will return a selector that matches a number of elements.
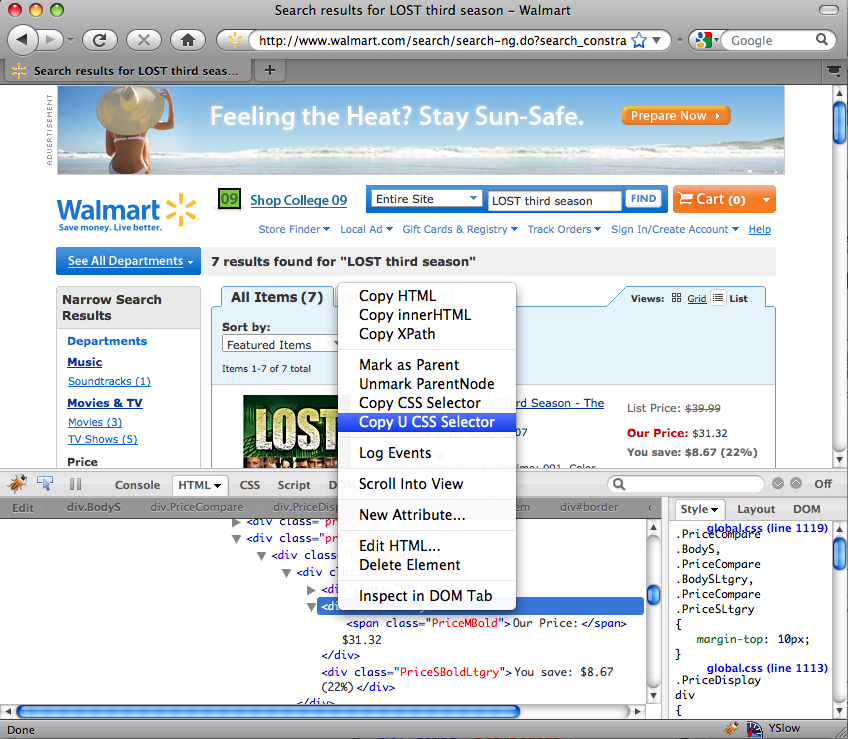
For our price element the CSS selector is
div.firstRow div.priceAvail>div>div.PriceCompare>div.BodyS
We can paste this into the small Ruby program we wrote earlier, replacing the “title” selector in the scraper’s process method. We’ll also change the name of the variable that’s returned from :page_name to :price.
require 'rubygems' require 'scrapi' scraper = Scraper.define do process "div.firstRow div.priceAvail>div>div.PriceCompare>div.BodyS", :price => :text result :price end url = URI.parse("http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=LOST+third+season&Find.x=17&Find.y=1&Find=Find") puts scraper.scrape(url)
When we run our program now we’ll see the item’s price.
$ ruby scrapitest.rb Our Price: $31.32
We still need to extract the price itself from the string but we have the information we want.
Incorporating Scraping Into Our Application
Now that we’ve successfully scraped a price from the site we can move back to our application and add this functionality in. We’ll do this by writing a class method in our Product model class to fetch the prices for any products without a price.
class Product < ActiveRecord::Base belongs_to :category def self.fetch_prices scraper = Scraper.define do process "div.firstRow div.priceAvail>div>div.PriceCompare>div.BodyS", :price => :text result :price end find_all_by_price(nil).each do |product| url = URI.parse("http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=" + CGI.escape(product.title) + "&Find.x=17&Find.y=1&Find=Find") product.update_attribute :price, scraper.scrape(url)[/[.0-9]+/] end end end
Our new fetch_prices method is made up mostly of the code we created in our test program. In the first part of the method we create the scraper that fetches the price from the page. Then we find all of the products that have no price and loop through them. For each product we create a URI to the search page that includes the product’s title, escaped with CGI.escape. With the result we get back from the scraper we then use a regular expression, /[.0-9]+/ , to get the numeric part from the text that is returned (which is in the form “Our Price: $99.99”). Once we’ve got the value we can update the product’s price.
We can test this now by running Product.fetch_prices in Rails’ console. (If this app was going into product we might want to turn this into a rake task.)
>> Product.fetch_prices => [#<Product id: 1, title: "LOST Third Season", price: 31.32, created_at: "2009-08-03 18:10:12", updated_at: "2009-08-05 20:46:31", category_id: nil>, #<Product id: 2, title: "Star Wars Episode IV: A New Hope", price: 13.86, created_at: "2009-08-03 18:11:31", updated_at: "2009-08-05 20:46:32", category_id: nil>, #<Product id: 3, title: "Webster College Dictionary", price: 17.21, created_at: "2009-08-03 18:11:47", updated_at: "2009-08-05 20:46:34", category_id: nil>]
There’s a slight pause as each price is fetched, then we can see all of our products each with its price as scraped from Walmart’s site. If we go back to our product page and reload it we’ll see the products listed along with their prices.
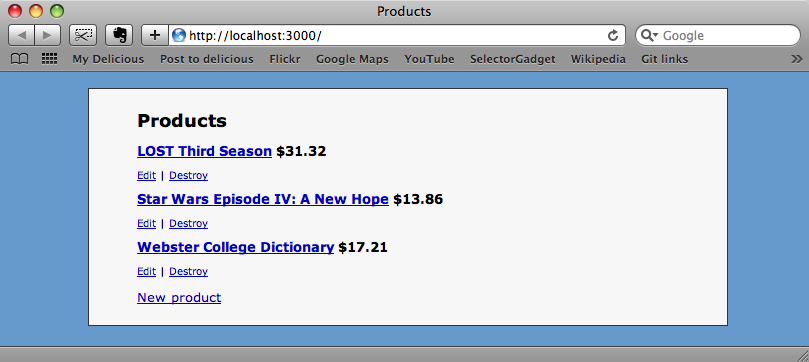
Further Adventures With ScrAPI.
We’ll finish off this episode by showing some of the other things that scrAPI can do. So far we’ve only fetched the content of a single element on a page but it’s just as easy to fetch multiple elements. Back in our test program we’ll add another call to the process method to get the item’s title.
require 'rubygems' require 'scrapi' scraper = Scraper.define do process "div.firstRow a.prodLink", :title => :text process "div.firstRow div.priceAvail>div>div.PriceCompare>div.BodyS", :price => :text result :price, :title end url = URI.parse("http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=LOST+third+season&Find.x=17&Find.y=1&Find=Find") puts scraper.scrape(url)
Now, as well as getting the price for the first item in the search results we’re fetching the title too. The CSS selector for this is just div.firstRow a.title
. When we run this program now we get a slightly different result. Instead of a string being returned we get a struct.
$ ruby scrapitest.rb #<struct #<Class:0x11fbc14> price="Our Price: $31.32", title=nil>
We can get at the attributes of this struct by changing the last part of our program so that we assign the result of the scrape to a variable then print out the properties from that.
product = scraper.scrape(url) puts product.title puts product.price
We’ll now see the title and price output.
$ ruby scrapitest.rb Lost: The Complete Third Season - The Unexplored Edition Our Price: $31.32
Returning Multiple Results
The page we’re scraping data from has multiple results on it, but we’re currently only getting the details for the first result. We can instead get the price and title for every result on the page. To do this we need to find a CSS selector generic enough to match each item. We can use Firequark again to get this. If we right-click on one of the results and select “Inspect Element” we can then right-click on the element in Firebug’s source view and select “Copy CSS Selector” from the Firequark menu.
When we select this option we’ll be asked for the number of elements we need to match. As there are seven results on the page we’ll enter 7 and click “OK”. The matching CSS selector will be copied to the clipboard. For our items it’s simply
div.prodInfo
This selector will match all of the items on the page, but how do we use it with scrAPI to return a list of items? The answer is to use nested scrapers.
scraper = Scraper.define do array :items process "div.item", :items => Scraper.define { process "a.prodLink", :title => :text process "div.priceAvail>div>div.PriceCompare>div.BodyS", :price => :text result :price, :title } result :items end
In our outer scraper we first call the array method, passing it the name of a variable. This means that the scraper knows it will be returning an array of values. We then call process, but because we want to return multiple values from each item we define a second scraper. The second scraper has two process methods which are similar to the ones we used earlier to fetch the price and title for the first item, but with div.firstRow removed from the selectors as we don’t need to match the first item any more because we’re already within an item in the outer selector.
Now our scraper will return an array of products. We can loop through the array and print out the title and price of each item.
url = URI.parse("http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=LOST+third+season&Find.x=17&Find.y=1&Find=Find") scraper.scrape(url).each do |product| puts product.title puts product.price puts end
When we run our program now we’ll see the list of results.
$ ruby scrapitest.rb Lost: The Complete Third Season - The Unexplored Edition Our Price: $31.32 Lost: The Complete Third Season - The Unexplored Experience (Spanish) Our Price: $50.32 Lost World: Season 3, The (Full Frame) Our Price: $20.86 Lost In Space: Season 3, Vol. 2 Our Price: $18.32 Lost In Space: Season 3, Vol. 1 (Full Frame, Widescreen) Our Price: $18.32 Lost: Season Three Score (2CD) Our Price: $15.88 Land Of The Lost: The Complete Third Season Our Price: $26.86
Getting Other Attributes
So far we’ve only got the text from the elements we’ve matched from our scraper, but what if we want to get an attibute, say the href of a link? In our scraper we match the anchor tag of an item as its text contains the item’s title. We can retrieve the link to the item’s page too adding another item to the hash of values we pass to process.
process "a.prodLink", :title => :text, :link => "@href"
To get the value of the href attribute we pass the name of the attribute with an @ in front of it. This will assign the value of the href attribute to the :link variable. To return the value from the scraper we just add the variable’s name to the result method.
result :price, :title, :link
We can then print out the link along with the title and price.
url = URI.parse("http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=LOST+third+season&Find.x=17&Find.y=1&Find=Find") scraper.scrape(url).each do |product| puts product.title puts product.price puts product.link puts end
Running our program one last time will show the links for each item.
$ ruby scrapitest.rb Lost: The Complete Third Season - The Unexplored Edition Our Price: $31.32 /catalog/product.do?product_id=5978156 Lost: The Complete Third Season - The Unexplored Experience (Spanish) Our Price: $50.32 /catalog/product.do?product_id=6537182 Lost World: Season 3, The (Full Frame) Our Price: $20.86 /catalog/product.do?product_id=10750968 Lost In Space: Season 3, Vol. 2 Our Price: $18.32 /catalog/product.do?product_id=3873349 Lost In Space: Season 3, Vol. 1 (Full Frame, Widescreen) Our Price: $18.32 /catalog/product.do?product_id=3551329 Lost: Season Three Score (2CD) Our Price: $15.88 /catalog/product.do?product_id=9875636 Land Of The Lost: The Complete Third Season Our Price: $26.86 /catalog/product.do?product_id=3899305
ScrAPI is fairly flexible when it comes to scraping data from webpages. It should be possible to scrape the data you want from any page, although if we were using this technique in a production application we’d want to implement some error handling. For example a search may return no results, or the price for certain items may appear in an element with a different class name.
