
#243 Beanstalkd and Stalker
- Download:
- source code
- mp4
- m4v
- webm
- ogv
No Rails Rumble desse ano, Ryan Bates e sua equipe criaram o site Go vs Go, onde você pode jogar Go (um jogo de tabuleiro) online. No site, você pode jogar contra outro jogador ou contra o computador. Quando você joga contra o computador, há um pequeno atraso após você mover sua pedra até o computador mover a dele. Isso acontece enquanto o computador calcula o seu movimento e, por padrão, prende um processo do Rails. Para evitar esse problema, a IA do jogo foi movida para um processo em segundo plano. Existem algumas maneiras de agendar processos em aplicações Rails, e a equipe do Go vs Go escolheu usar o beanstalkd. Nesse episódio vamos dar uma olhada no beanstalkd e na gem Stalker.
Começando com Beanstalkd
Se você está no OSX, há uma maneira fácil de instalar o beanstalkd, que é através do Homebrew. Nesse caso, você só precisa executar:
$ brew install beanstalkd
Depois de instalado, podemos iniciar o servidor do Beanstalkd executando o comando beanstalkd. Para executar como um processo daemon, podemos adicionar a opção -d.
$ beanstalkd -d
Para usar o Beanstalkd com Ruby vamos precisar instalar a gem beanstalk-clienk.
$ gem install beanstalk-client
Há instruções de como usar o Beanstalk com Ruby no site do Beanstalkd. Precisamos criar um novo Beanstalk::Pool e usar seu método put para adicionar uma tarefa na fila. E para trazer um item da fila, usamos o método reserve. Ele irá aguardar até uma tarefa estar disponível na fila e então irá retorná-la. Podemos assim processar a tarefa e então usar delete para removê-la da fila.
Vamos demonstrar isso em duas sessões irb. Em cada uma vamos criar um novo pool do Beanstalk em localhost:11300.
$ irb
ruby-1.9.2-p0 > require 'beanstalk-client'
=> true
ruby-1.9.2-p0 > beanstalk = Beanstalk::Pool.new(['localhost:11300'])
=> #<Beanstalk::Pool:0x00000100a9f8e8 @addrs=["localhost:11300"], @watch_list=["default"], @default_tube=nil, @connections={"localhost:11300"=>#<Beanstalk::Connection:0x00000100a9f7f8 @mutex=#<Mutex:0x00000100a9f780>, @waiting=false, @addr="localhost:11300", @socket=#<TCPSocket:fd 3>, @last_used="default", @watch_list=["default"]>}>
ruby-1.9.2-p0 >$ irb
ruby-1.9.2-p0 > require 'beanstalk-client'
=> true
ruby-1.9.2-p0 > beanstalk = Beanstalk::Pool.new(['localhost:11300'])
=> #<Beanstalk::Pool:0x00000101919bf8 @addrs=["localhost:11300"], @watch_list=["default"], @default_tube=nil, @connections={"localhost:11300"=>#<Beanstalk::Connection:0x00000101919978 @mutex=#<Mutex:0x000001019198d8>, @waiting=false, @addr="localhost:11300", @socket=#<TCPSocket:fd 3>, @last_used="default", @watch_list=["default"]>}>
ruby-1.9.2-p0 >Vamos adicionar uma tarefa na fila na janela superior, usando o put.
ruby-1.9.2-p0 > beanstalk.put "hello" => 1
Na outra janela, vamos trazer aquela tarefa com reserve.
ruby-1.9.2-p0 > job = beanstalk.reserve => (job server=localhost:11300 id=1 size=5)
Podemos então ver o body da tarefa e apagá-la da fila.
ruby-1.9.2-p0 > job.body => "hello" ruby-1.9.2-p0 > job.delete => false
Se tentarmos dar reserve em outra tarefa agora, o comando vai aguardar, pois não há tarefas na fila.
ruby-1.9.2-p0 > job = beanstalk.reserve
Agora que adicionamos outra tarefa, ela será retornada imediatamente.
ruby-1.9.2-p0 > beanstalk.put "bacon" => 2
ruby-1.9.2-p0 > job = beanstalk.reserve => (job server=localhost:11300 id=2 size=5)
A nova tarefa é processada imediatamente. Isso ajuda na resposta do Go vs Go, pois significa que o computador vai responder assim que possível.
Usando o Beanstalk em uma aplicação Rails
Vamos ver como usar o Beanstalkd em uma aplicação Rails. Temos uma aplicação simples que nos permite criar cidades. Tudo que precisamos fazer é fornecer um código postal e uma cidade será criada. O nome da cidade virá de um site externo.
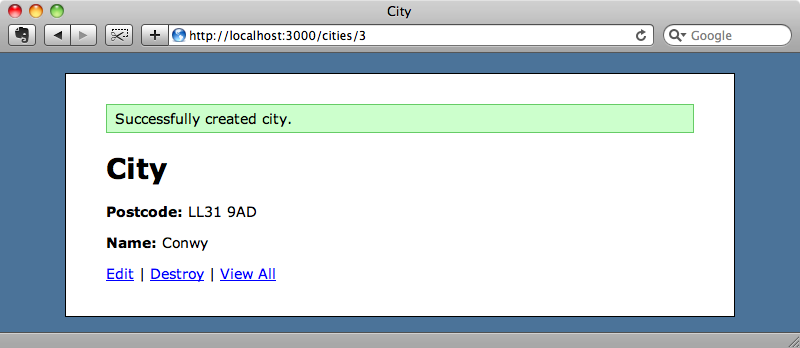
Embora trazer o nome da cidade seja geralmente uma chamada rápida, uma requisição separada pode ser lenta, por isso vamos movê-la para um processo em segundo plano.
Antes estavamos usando a gem Beanstalk client diretamente, mas em uma aplicação Rails vamos usar outra gem chamada Stalker. Ela usa a gem cliente e fornece uma interface melhor para trabalhar. Para usar o Stalker em nossa aplicação Rails, só precisamos adicioná-la ao Gemfile.
source 'http://rubygems.org' gem 'rails', '3.0.3' gem 'nifty-generators' gem 'sqlite3-ruby', :require => 'sqlite3' gem 'stalker'
E vamos instalar executando o bundle.
Podemos agora mover o código que traz os nomes das cidades para um processo separado em segundo plano. A action create atualmente salva a nova cidade e então chama um método do modelo City chamado fetch_name para determinar o nome da cidade. Esse método chama uma API externa que traz o nome da cidade. É isso que queremos mover para um processo em segundo plano.
def create @city = City.new(params[:city]) if @city.save @city.fetch_name redirect_to city_path(@city), :notice => "Successfully created city." else render :action => 'new' end end
Vamos modificar o código para que, em vez de chamar @city.fetch_name, ele adicione uma tarefa na nossa fila. Podemos fazer isso chamando Stalker.enqueue. Precisamos dar um identificador para a nova tarefa, então vamos chamá-la de city.fetch_name. Podemos também passar opções para a tarefa; vamos passar o id da cidade que acabamos de salvar.
def create @city = City.new(params[:city]) if @city.save Stalker.enqueue("city.fetch_name", :id => @city.id) redirect_to city_path(@city), :notice => "Successfully created city." else render :action => 'new' end end
Agora precisamos criar uma nova tarefa Stalker para lidar com isso. Podemos em qualquer lugar na nossa aplicação Rails; vamos criar no diretório config, um arquivo chamado jobs.rb.
Stalker tem uma API simples para gerenciamento de tarefas. Tudo que precisamos fazer é chamar o método job e passar um identificador. Esse método também recebe um bloco, que tem como argumentos, os argumentos passados para o Stalker.enqueue anteriormente. Nesse bloco, pegamos a cidade com o id correto e chamamos o método fetch_name. O Stalker não carrega o ambiente do Rails por padrão, por isso é necessário dar require no arquivo config/environment.rb na primeira linha do código abaixo:
require File.expand_path("../environment", __FILE__) job "city.fetch_name" do |args| City.find(args["id"]).fetch_name end
Podemos executar nossas tarefas executando o comando stalk passando o nome do arquivo que queremos executar.
$ stalk ./config/jobs.rb
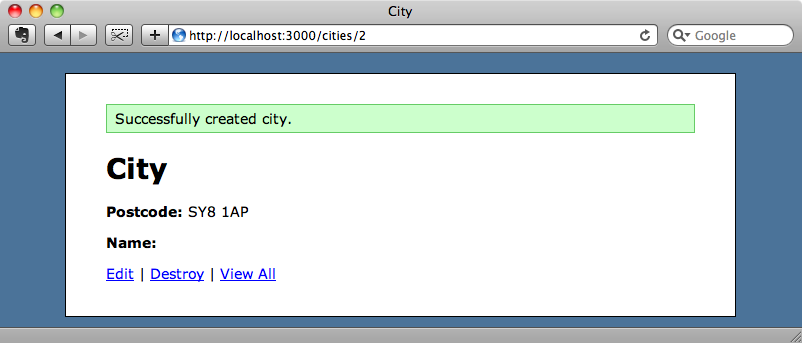
Temos o Beanstalkd executando. Se criarmos uma nova cidade, seu nome ficará em branco.
Quando recarregamos a página algumas vezes, o nome aparece.
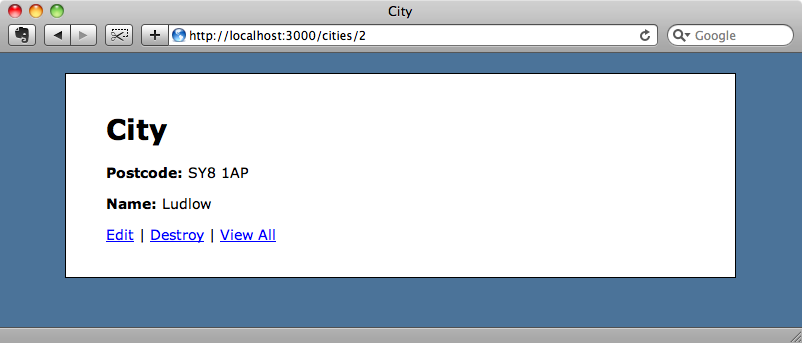
Isso mostra que a tarefa está sendo processada com sucesso em segundo plano. Se olharmos o log, vamos ver a tarefa listada.
[2010-12-09 19:04:49 +0000] -> city.fetch_name (id=2) [2010-12-09 19:04:50 +0000] -> city.fetch_name finished in 374ms
Otimizando o processo em segundo plano
Um problema da nossa tarefa é que ela está carregando todo o ambiente Rails. Se tivermos vários processos para lidar com as tarefas, isso vai nos levar a um gasto muito grande de memória. Ter o ambiente Rails disponível não é necessário e podemos fazer o processo mais eficiente sem ele. Para fazer isso, vamos alterar a tarefa para ela acessar o banco de dados sem o ActiveRecord.
require 'sqlite3' require 'json' require 'net/http' RAILS_ENV = ENV["RAILS_ENV"] || "development" db = SQLite3::Database.new(File.expand_path( "../../db/#{RAILS_ENV}.sqlite3", __FILE__)) job "city.fetch_name" do |args| postcode = db.get_first_value("SELECT postcode FROM cities WHERE id=?", args["id"]) url = "http://ws.geonames.org/postalCodeLookupJSON? postalcode=#{CGI.escape(postcode)}&country=GB" json = Net::HTTP.get_response(URI.parse(url)).body name = JSON.parse(json)["postalcodes"].first["placeName"] db.execute("UPDATE cities SET name=? WHERE id=?", args["id"], name) end
No código acima, pegamos o código postal no banco de dados e trazemos o nome da cidade através da API. Depois fazemos o parser da resposta JSON para pegar o nome da cidade. E assim atualizamos o registro no banco de dados. Tudo isso é feito sem usar o modelo City ou qualquer coisa da aplicação Rails. Isso vai manter o processo muito mais enxuto.
Tratamento de Erros
O que acontece se uma exceção é lançada quando tentamos pegar o nome da cidade? Nesses casos o Stalker vai gerar o log do erro e vai tentar executar um manipulador de erros. Podemos criar um manipulador escrevendo um método error.
error do |exception| # Code to handle the error. end
Quando isso acontece o Stalker vai abandonar a tarefa no Beanstalk, isso significa que o Beanstalk não vai tentar colocá-la na fila novamente, a menos que a gente use o comando kick. Para isso, conectamos por telnet diretamente no Benstalkd.
$ telnet localhost 11300 Trying ::1... Connected to localhost. Escape character is '^]'.
Depois de conectado, vamos executar o comando kick, passando o número de tarefas que queremos colocar de volta na fila.
kick 10 KICKED 0
Não temos qualquer tarefa abandonada, então recebemos KICKED 0 como resposta.
Agora podemos tratar exceções de uma tarefa, mas e se o processo de segundo plano morrer completamente? Devemos monitorar o processo para assegurarmos que ele está funcionando. Podemos fazer isso usando a ferramenta God. Falamos dessa ferramenta em detalhes no episódio 130. Abaixo está um arquivo de configuração para executar tarefas Stalker em segundo plano. Uma vantagem deste método é que ele automaticamente faz o daemon do processo para que nós não tenhamos que nos preocupar com isso.
Se você olhar o arquivo de configuração abaixo, vai ver que ele chama o stalk com nosso arquivo jobs.rb passado como parâmetro. O resto do arquivo é um conjunto bastante comum de configurações que assegura que ele permaneça em funcionamento e não comece a usar muita memória ou CPU.
# run with: god -c config/god.rb RAILS_ROOT = File.expand_path("../..", __FILE__) God.watch do |w| w.name = "anycity-worker" w.interval = 30.seconds w.env = {"RAILS_ENV" => "production"} w.start = "/usr/bin/stalk #{RAILS_ROOT}/config/jobs.rb" w.log = "#{RAILS_ROOT}/log/stalker.log" w.start_if do |start| start.condition(:process_running) do |c| c.running = false end end w.restart_if do |restart| restart.condition(:memory_usage) do |c| c.above = 50.megabytes c.times = [3, 5] # 3 out of 5 intervals end restart.condition(:cpu_usage) do |c| c.above = 50.percent c.times = 5 end end w.lifecycle do |on| on.condition(:flapping) do |c| c.to_state = [:start, :restart] c.times = 5 c.within = 5.minute c.transition = :unmonitored c.retry_in = 10.minutes c.retry_times = 5 c.retry_within = 2.hours end end end
Persistindo Beanstalk
Só mais uma coisa para se manter em mente é que o Beanstalk por padrão não é persistente. Se você executá-lo como fizemos com opção -d e o processo morrer em seguida, todas as tarefas que estavam na fila aguardando para serem processadas são perdidas, pois elas são armazenadas na memória. Para tornar persistente, podemos executá-lo com a opção -b e passar-lhe o caminho para um diretório binlog.
beanstalkd -d -b /Users/eifion/binlog
Dessa forma a fila será restaurada caso o processo falhe.
