
#243 Beanstalkd and Stalker
- Download:
- source code
- mp4
- m4v
- webm
- ogv
Ryan Bates y su equipo crearon la aplicación Go vs Go para la edición de este año de la Rails Rumble. Se trata de una aplicación que sirve para jugar en línea al juego de Go, donde se pueden disputar partidas contra otro jugador o contra la aplicación. Cuando uno juega contra la máquina, hay un pequeño retardo desde que se pone la pieza hasta que el ordenador juega. Este intervalo de tiempo puede llegar a ser grande porque al programa le lleva un tiempo calcular su próximo movimiento, tiempo durante el cual habrá un proceso Rails bloqueado. Para evitar este problema se movió la inteligencia artificial del juego a una tarea asíncrona. Hay varias formas de encolar este tipo de tareas en una aplicación Rails y el equipo de Go vs Go decidió utilizar Beanstalk. En este episodio veremos Beanstalk y su gema hermana Stalker.
Cómo empezar con Beanstalk
Si estamos ejecutando OSX la forma más sencilla de instalar Beanstalk es mediante Homebrew, en cuyo caso tan sólo tenemos que ejecutar
$ brew install beanstalkd
Tras la instalación de Beanstalk podemos arrancar el servidor ejecutando la orden beanstalkd. Para ejecutarlo como demonio podemos añadir la opción -d.
$ beanstalkd -d
Tenemos que instalar la gema cliente de Beanstalk para poder trabajar con Beanstalk, lo que se hace como con cualquier otra gema.
$ gem install beanstalk-client
En la página de Beanstalk hay instrucciones acerca del uso de Beanstalk con Ruby. Tenemos que crear una nueva instancia de Beanstalk::Pool y usar el método put para añadir tareas a la cola. Para recuperar luego un elemento de la cola puede usarse el método reserve, que esperará hasta que aparezca una tarea libre en la cola y la devolverá. Tras esto podemos procesar la tarea y cuando hayamos terminado con ella usar delete para eliminarla de la cola.
Vamos a demostrar esto con dos sesiones de irb. En cada una de elllas crearemos una nueva cola en localhost:11300.
$ irb
ruby-1.9.2-p0 > require 'beanstalk-client'
=> true
ruby-1.9.2-p0 > beanstalk = Beanstalk::Pool.new(['localhost:11300'])
=> #<Beanstalk::Pool:0x00000100a9f8e8 @addrs=["localhost:11300"], @watch_list=["default"], @default_tube=nil, @connections={"localhost:11300"=>#<Beanstalk::Connection:0x00000100a9f7f8 @mutex=#<Mutex:0x00000100a9f780>, @waiting=false, @addr="localhost:11300", @socket=#<TCPSocket:fd 3>, @last_used="default", @watch_list=["default"]>}>
ruby-1.9.2-p0 >$ irb
ruby-1.9.2-p0 > require 'beanstalk-client'
=> true
ruby-1.9.2-p0 > beanstalk = Beanstalk::Pool.new(['localhost:11300'])
=> #<Beanstalk::Pool:0x00000101919bf8 @addrs=["localhost:11300"], @watch_list=["default"], @default_tube=nil, @connections={"localhost:11300"=>#<Beanstalk::Connection:0x00000101919978 @mutex=#<Mutex:0x000001019198d8>, @waiting=false, @addr="localhost:11300", @socket=#<TCPSocket:fd 3>, @last_used="default", @watch_list=["default"]>}>
ruby-1.9.2-p0 >Añadamos una tarea a la cola en la ventana superior utilizando put.
ruby-1.9.2-p0 > beanstalk.put "hello" => 1
En la otra ventana podemos capturar esta tarea con reserve.
ruby-1.9.2-p0 > job = beanstalk.reserve => (job server=localhost:11300 id=1 size=5)
Podemos inspeccionar el atributo body de la tarea y sacarla de la cola.
ruby-1.9.2-p0 > job.body => "hello" ruby-1.9.2-p0 > job.delete => false
Si ahora intentamos reservar otra tarea nos quedaremos esperando porque no existen más tareas en la cola.
ruby-1.9.2-p0 > job = beanstalk.reserve
El proceso se desbloqueará inmediatamente en cuanto añadamos una nueva tarea a la cola.
ruby-1.9.2-p0 > beanstalk.put "bacon" => 2
ruby-1.9.2-p0 > job = beanstalk.reserve => (job server=localhost:11300 id=2 size=5)
No se está realizando ningún tipo de sondeo periódico sino que la nueva tarea se procesa de forma inmediata, en cuanto está disponible. Esto mejora la velocidad percibida de la aplicación Go vs Go porque la máquina responde tan pronto como le es posible.
Cómo usar Beanstalk en una aplicación Rails
Veamos cómo usar Beanstalk en nuestras aplicaciones Rails. Tenemos una aplicación muy sencilla que nos permite crear ciudades. Lo único que tenemos que hacer es introducir un código postal y se creará una ciudad cuyo nombre se obtendrá de una aplicación externa.
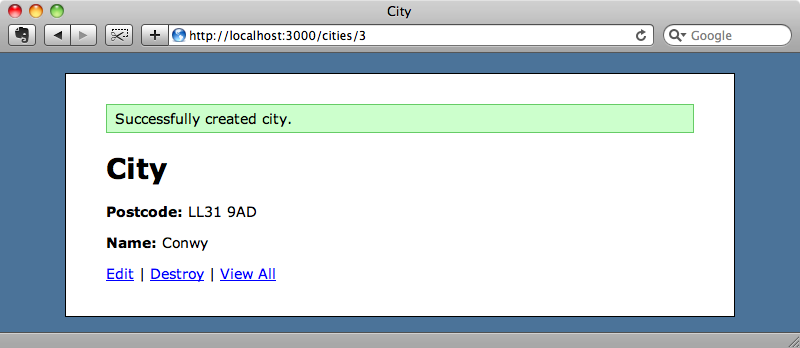
Aunque el proceso de recuperar el nombre de la ciudad es por lo general lo suficientemente rápido, puede ser que en algún momento la respuesta sea lenta por lo que hemos decidido que lo vamos a mover a un proceso separado.
Si bien en Rails podemos trabajar directamente con la gema cliente de Beanstalk, nosotros preferimos usar otra gema llamada Stalker, que es un recubrimiento de la gema cliente que proporciona un interfaz más cómoda. Para usar Stalker tan sólo tenemos que añadir la gema al Gemfile.
source 'http://rubygems.org' gem 'rails', '3.0.3' gem 'nifty-generators' gem 'sqlite3-ruby', :require => 'sqlite3' gem 'stalker'
Después de esto ya podemos instalar la gema con bundle.
Ya podemos pasar a mover el código que recupera los nombres de ciudades a su propio proceso. La acción create ahora mismo guarda la nueva ciudad y luego llama a un método del modelo City llamado fetch_name para establecer el nombre de la ciudad. Este método invoca a una API externa que obtiene el nombre de la ciudad y que es exactamente lo que queremos mover a la tarea asíncrona.
def create @city = City.new(params[:city]) if @city.save @city.fetch_name redirect_to city_path(@city), :notice => "Successfully created city." else render :action => 'new' end end
Modificaremos el código para que en lugar de llamar a @city.fetch_name se añada una tarea a la cola, con Stalker.enqueue. A la nueva tarea tenemos que darle un identificador, que será city.fetchname. A la tarea le podemos pasar cualquier otra opción que deseemos, por ejemplo el id de la ciudad que hemos acabado de crear.
def create @city = City.new(params[:city]) if @city.save Stalker.enqueue("city.fetch_name", :id => @city.id) redirect_to city_path(@city), :notice => "Successfully created city." else render :action => 'new' end end
A continuación debemos crear una tarea de Stalker para gestionar esto. Crearemos un archivo llamado jobs.rb en el directorio /config de nuestra aplicación.
La API de Stalker para gestionar tareas es muy sencilla. Tan sólo tenemos que llamar al método job y pasarle un identificador. Este método recibe un bloque que tiene como argumentos los mismos que se le han pasado Stalker.enqueue. En este bloque encontramos la instancia de City que tiene el id correspondiente e invocamos el método fetch_name sobre ella. Stalker no es específico de Rails, por lo que el entorno de Rails no está cargado por defecto. Para ello requeriremos el fichero config/environment.rb en la primera línea.
require File.expand_path("../environment", __FILE__) job "city.fetch_name" do |args| City.find(args["id"]).fetch_name end
Para ejecutar nuestras tareas podemos ejecutar la orden stalk y pasarle el nombre del fichero que queremos ejecutar.
$ stalk ./config/jobs.rb
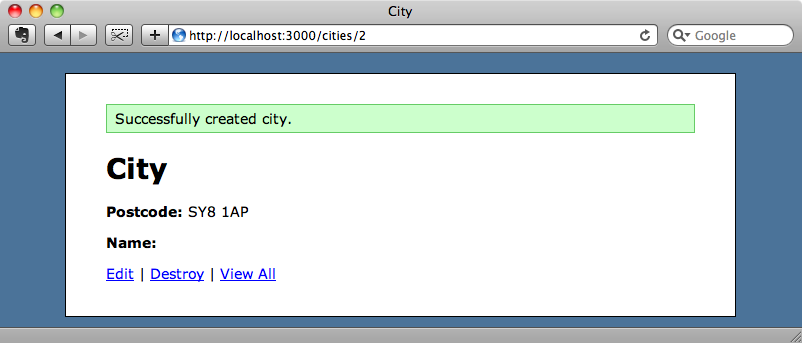
Podemos hacer la prueba ya porque aún tenemos beanstalkd en ejecución. Si creamos una nueva ciudad el nombre estará vacío.
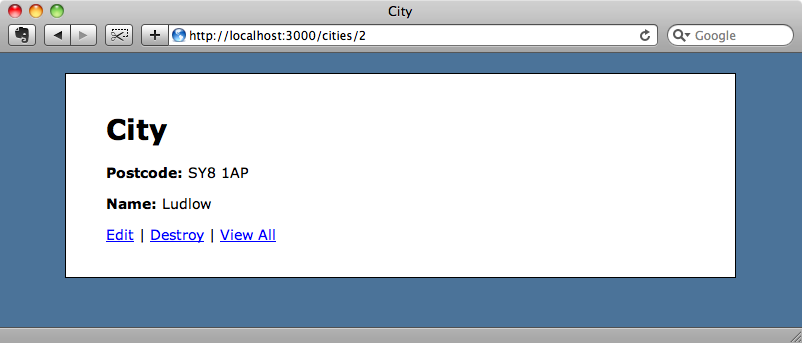
Pero si refrescamos la página uno o dos segundos después, aparecerá el nombre.
Si miramos en la traza de la aplicación veremos que la tarea se ha ejecutado.
[2010-12-09 19:04:49 +0000] -> city.fetch_name (id=2) [2010-12-09 19:04:50 +0000] -> city.fetch_name finished in 374ms
Optimización del proceso asíncrono
El problema que tiene nuestra tarea es que carga todo el entorno de Rails. Esto hará que si queremos lanzar varios agentes para procesar múltiples tareas a la vez tengamos que emplear mucha memoria. Es muy cómodo tener el entorno de Rails cargado, pero no es imprescindible. Podemos hacer que el código de la tarea sea mucho más eficiente si cambiamos el código de la tarea para que acceda a la base de datos directamente en lugar de usar ActiveRecord.
require 'sqlite3' require 'json' require 'net/http' RAILS_ENV = ENV["RAILS_ENV"] || "development" db = SQLite3::Database.new(File.expand_path( "../../db/#{RAILS_ENV}.sqlite3", __FILE__)) job "city.fetch_name" do |args| postcode = db.get_first_value("SELECT postcode FROM cities WHERE id=?", args["id"]) url = "http://ws.geonames.org/postalCodeLookupJSON? postalcode=#{CGI.escape(postcode)}&country=GB" json = Net::HTTP.get_response(URI.parse(url)).body name = JSON.parse(json)["postalcodes"].first["placeName"] db.execute("UPDATE cities SET name=? WHERE id=?", args["id"], name) end
En el código anterior recuperamos de la base de datos el código postal de la ciudad y luego obtenemos el nombre de la ciudad a partir del JSON devuelto por la API, por último actualizamos el registro apropiado en la base de datos. Todo esto sin usar el modelo City, lo que hará que la tarea sea mucho más ligera.
Gestión de errores
¿Qué pasa si se eleva una excepción al intentar obtener el nombre de una ciudad? En estos casos Stalker trazará el error e intentará ejecutar una función de manejo de errores. Podemos hacerlo creando el método error.
error do |exception| # Code to handle the error. end
Cuando esto ocurra Stalker enterrará la tarea, lo que significa que Beanstalk no intentará ejecutarla de nuevo a no ser que la resucitemos de una patada. Para hacerlo tenemos que hacer telnet directamente a Beanstalk.
$ telnet localhost 11300 Trying ::1... Connected to localhost. Escape character is '^]'.
Una vez que estemos conectados podemos ejecutar la orden kick pasando el número de tareas que queremos meter de nueva en la cola.
kick 10 KICKED 0
Ahora mismo no tenemos tareas enterradas por lo que hemos recibido la respuesta KICKED 0.
Queda claro que podemos controlar las excepciones que ocurran dentro de una tarea pero ¿qué pasa si el proceso muere repentinamente? Para estas contingencias deberíamos monitorizar dicho proceso con una herramienta como God, que vimos en detalle en el episodio 130 por lo que si no estamos familiarizados con este tipo de herramientas merece una pena leer ese episodio. A continuación se muestra un fichero de configuración para tareas de Stalker. Una ventaja de esta técnica es que el proceso se demoniza automáticamente por lo que no nos tendremos que preocupar por eso.
En el fichero de configuración podremos ver que se invoca la orden stalk pasando como parámetro nuestro fichero jobs.rb. El resto del fichero son las condiciones habituales que se usan para garantizar que el proceso está levantado y que no usa demasiada memoria o CPU.
# run with: god -c config/god.rb RAILS_ROOT = File.expand_path("../..", __FILE__) God.watch do |w| w.name = "anycity-worker" w.interval = 30.seconds w.env = {"RAILS_ENV" => "production"} w.start = "/usr/bin/stalk #{RAILS_ROOT}/config/jobs.rb" w.log = "#{RAILS_ROOT}/log/stalker.log" w.start_if do |start| start.condition(:process_running) do |c| c.running = false end end w.restart_if do |restart| restart.condition(:memory_usage) do |c| c.above = 50.megabytes c.times = [3, 5] # 3 out of 5 intervals end restart.condition(:cpu_usage) do |c| c.above = 50.percent c.times = 5 end end w.lifecycle do |on| on.condition(:flapping) do |c| c.to_state = [:start, :restart] c.times = 5 c.within = 5.minute c.transition = :unmonitored c.retry_in = 10.minutes c.retry_times = 5 c.retry_within = 2.hours end end end
Persistencia
Debe tenerse en cuenta que por defecto Beanstalk no es persistente. Si intentamos ejecutarlo con la opción -d y el proceso muere por cualquier motivo, se perederán todas las tareas encoladas que estaban esperando a ser ejecutadas. Para que el servidor Beanstalk utilice colas persistentes hay que ejecutarlo con la opción -b y pasar la ruta de un directorio para guardar los archivos binarios.
beanstalkd -d -b /Users/eifion/binlog
De esta forma se puede recuperar la cola si el proceso tiene algún fallo catastrófico.
