
#168 Feed Parsing
- Download:
- source code
- mp4
- m4v
- webm
- ogv
下面显示的是一个用Rails开发的博客程序的主页。我们想集成一些其他网站的信息来让这个网站变得更加丰富。我们打算加入一个链接列表指向另外一个Rails相关的站点,比如ASCIIcasts上最新文章的列表。
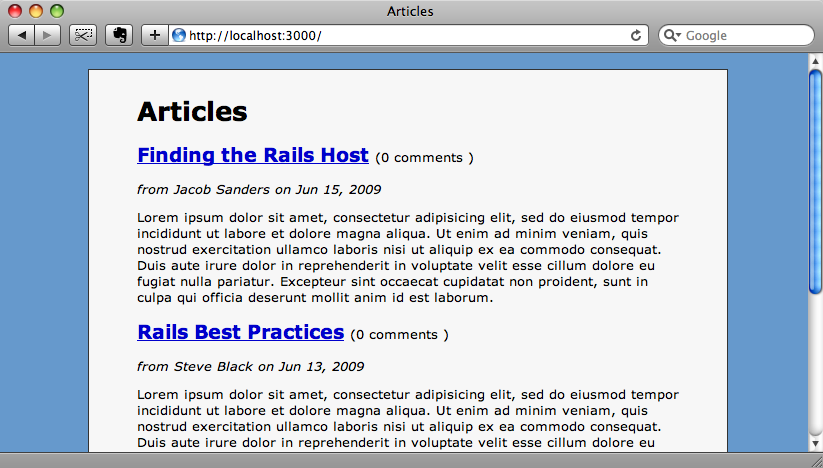
访问asciicasts.com,我们可以看到主页上最新文章的列表,但是我们如何把这些数据弄到我们的网站上来呢?我们可以通过页面抓取,抓到页面的HTML数据,通过解析得到我们想要的数据,这是一种可行的方法,不过有很多缺点。比如,如果网站的站长改变了页面的结构,那么我们的解析代码就没法正确地抽取出数据了。
现在更好的方法是使用RSS订阅点。ASCIIcasts站有一个RSS订阅点包含了所有集的列表,所以不需要抓取站点页面,我们只需要从订阅点来提取我们需要的数据就好了。
Feedzirra
Ruby里面有很多解析RSS订阅点的方法,不过最佳方案之一是一个叫Feedzirra的gem。Feedzirra最大的优势是它的速度,它可以非常快地解析订阅点,还有一个特点就是它可以解析很多不同类型的订阅点。
安装Feedzirra前,我们需要看看http://gems.github.com是不是在我们的gem源列表中。如果还没有,那我们把它先加上。
gem sources -a http://gems.github.com
现在我们就可以安装这个gem了: 控制台代码
sudo gem install pauldix-feedzirra
安装这个gem的时候会同时安装一些其他依赖的包。都装完了,我们还需要在程序的/config/environment.rb里面加入对这个gem的引用。
config.gem "pauldix-feedzirra", :lib => "feedzirra", :source => "http://gems.github.com"
搞定,我们可以开始在我们的程序里解析RSS订阅点了。
提起取订阅点
订阅点的内容会显示在我们站点的主页上,但是我们不想在用户每次访问这个页面的时候都去读取订阅点的内容,那样太费时费力了。最好是能把订阅点的内容缓存在本地。缓存订阅点的内容可以有各种各样的方法,我们想把它保存在数据库中,创建一个数据模型来表示订阅点中的每一个条目。我们给这个数据模型起名叫feed_entry。这个数据模型用四个属性来存储一个条目的数据,name用来保存标题,summary用来保存内容,url保存条目的链接,published_at保存条目创建的时间,还有就是guid用来保存一个条目的唯一标识符,我们用它来去除重复。
我们用下面的命令来创建数据模型
script/generate model feed_entry name:string summary:text url:string published_at:datetime guid:string
然后执行数据迁移任务来创建数据库表。
rake db:migrate
解析订阅点和更新条目的逻辑要加到FeedEntry类里面去。首先我们要定义一个方法来解析订阅点并且把新的条目添加到数据库中去。为此我们先定义一个类方法update_from_feed。
def self.update_from_feed(feed_url) feed = Feedzirra::Feed.fetch_and_parse(feed_url) feed.entries.each do |entry| unless exists? :guid => entry.id create!( :name => entry.title, :summary => entry.summary, :url => entry.url, :published_at => entry.published, :guid => entry.id ) end end end
这个方法有一个参数,是给Feedzirra用来解析的订阅点URL。Feedzirra提取订阅点,然后解析,然后循环遍历每一个条目把他们加到数据库中去。这个方法中使用了ActiveRecord中的exists?方法,通过条目的guid来判断一个条目是不是已经在数据库中了。
现在,我们可以在控制台上试试我们的新方法,从ASCIIcasts的订阅点上提取条目然后保存到数据库中去。
>> FeedEntry.update_from_feed("http://asciicasts.com/episodes.xml")提取和解析订阅点会有几秒钟的延时,然后你可以看到返回了一个很长的FeedZilla对象的数组。都完成后,数据库中应该已经有了我们要的条目。
>> FeedEntry.count => 61
如果我们要再运行一遍刚才的命令,它只会把上次运行后才有的新条目添加到数据库中去。为了及时同步订阅点的数据,我们可以用一个计划任务来定期提取订阅点的信息。164集中讲到的叫Whenever的gem可以用来设定这样的计划任务。
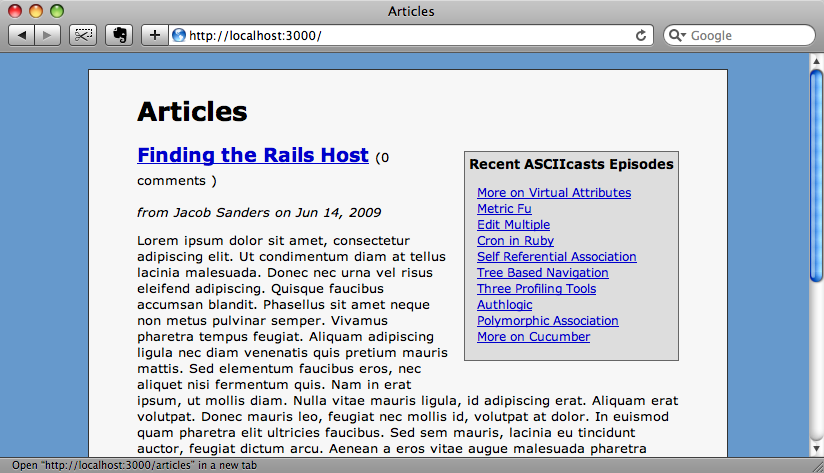
数据库中有了我们要的订阅点的条目,我们就可以改一改我们的视图代码来显示最新的条目了。在文章的索引视图的最上面,我们可以加入下面的代码来显示10条最新的条目
<div id="recent_episodes"> <h3>Recent ASCIIcasts Episodes</h3> <ul> <% for entry in FeedEntry.all(:limit => 10, :order => "published_at desc") %> <li><%= link_to h(entry.name), entry.url %></li> <% end %> </ul> </div>
给div加一些CSS,我们让列表显示在文章页面的右上角。
#recent_episodes { float: right; border: solid 1px #666; margin: 8px 0 16px 16px; padding: 4px; background-color: #DDD; }
#recent_episodes h3 { margin: 0; font-size: 1em; }
#recent_episodes ul { list-style: none; margin-left: 8px; padding-left: 0; }
#recent_episodes a { font-size: 0.9em; }现在我们的页面上有了一个区域,可以显示ASCIIcasts的最新文章了。
更频繁的更新
如果我们不需要很频繁地查看订阅点的内容是否有更新,那么之前我们写的代码可以工作地很好。但是如果我们要每十分钟左右就查看一次,那么现在这个方法就不是效率最高的了。每一次我们都要把整个订阅点的内容提取出来,大部分时候里面的数据都没有变化,所以提取整个订阅点的内容,既浪费时间又浪费带宽。
幸好Feedzirra提供了获取订阅点更新的方法。看一看Feedzirra的例子程序,你会发现有一个方法可以只提取订阅点中上次提取以后的更新部分。
# updating a single feed updated_feed = Feedzirra::Feed.update(feed)
update方法使用ETags来判断一个订阅点从上次更新以后是不是有变化,如果有才会提取并解析。还有一个new_entries方法能够返回新条目的集合。
写这个例子程序的时候,我没法让它跑起来,但是我的代码应该没问题,可以让你频繁地从订阅点上提取更新的内容。和之前创建的update_from_feed一样,我们要再给FeedEntry类加上一个方法。这个方法会不断地轮询订阅点,然后把更新的条目添加到数据库中去。
我们的新方法会使用把条目写到数据库的那些代码,所以我们先把那些代码抽取到一个单独的方法中去。
class FeedEntry < ActiveRecord::Base def self.update_from_feed(feed_url) feed = Feedzirra::Feed.fetch_and_parse(feed_url) add_entries(feed.entries) end private def self.add_entries(entries) entries.each do |entry| unless exists? :guid => entry.id create!( :name => entry.title, :summary => entry.summary, :url => entry.url, :published_at => entry.published, :guid => entry.id ) end end end end
现在我们来写这个新方法,我们给它起名叫update_from_feed_continuously。
def self.update_from_feed_continuously(feed_url, delay_interval = 15.minutes) feed = Feedzirra::Feed.fetch_and_parse(feed_url) add_entries(feed.entries) loop do sleep delay_interval.to_i feed = Feedzirra::Feed.update(feed) add_entries(feed.new_entries) if feed.updated? end end
这个方法定义和update_from_feed很像,只是多一个参数指定轮询订阅点的频率。开始先提取整个订阅点的内容,把条目都加到数据库中,然后就进入了一个死循环,休眠一段时间后,就查看订阅点是不是有更新,如果有就把新的条目写入数据库。
那么我们现在就有了两个从RSS订阅点提取条目的方法了,一个适用于计划任务,另一个可以用守护进程来实现,适合于需要频繁查看订阅点更新的情况。
需要注意的是,在守护进程中用死循环并不是一个最好的方式。更好的方法,可以看看129集,里面讲了如何用一个守护进程gem来创建后台进程。
